
반응형

Cluster Maintenance
강의 개요
- 운영체제 업그레이드
- 클러스터 업그레이드, 클러스터 end to end 업그레이드
- 백업과 복원
OS Upgrade
- 유지보수 목적으로 노드를 제거해야 하는 시나리오에 대해 논의해보자. 소프트웨어 기반 업그레이드나 패치 적용, 보안 패치 등을 클러스터에 적용하는 것이다.
- 노드와 파드가 응용 프로그램을 제공해준다. 허나 노드 중 하나가 다운이되면 어떻게 되는가?
- 파드가 접근이 불가능해진다.
- 예를 들어 레플리카셋으로 구성된 파드가 있다면 노드가 죽어도 파드가 계속 유지될 것이다. 만약 레플리카셋으로 구성되어 있지 않다면?
- 노드가 중지되면 파드는 영향을 받고 다른 노드에 올라오지 않으니 사용자가 애플리케이션을 이용하는데 영향을 줄것이다.
- 노드가 Up 상태로 변경되면 Kubelet에서 절차가 시작되고 파드를 띄우게된다.
- 그러나 노드가 5분 이상 다운되면 해당 노드에서 파드는 제거되고 쿠버네티스는 죽은 것으로 여긴다.
- 파드가 복구되길 기다리는 시간은 --pod-eviction-timeout 으로 조정가능하다.
- 그러나 해당 flag는 v1.26 이후로 deprecated 되었다.
- eviction timout이 발생한 후 노드가 다시 활성화되면 pod가 준비될 수 있어도 다른 노드로 넘어가기 때문에 노드는 공백이 된다.
- 따라서 노드에서 실행할 유지보수 작업(maintenance)이 있다면, 노드에서 실행되는 작업이 다른 replicas를 갖고 있다는 걸 안다면, 그리고 그게 단기간 중단되어도 괜찮다면, 그리고 노드가 5분 내로 다시 온라인으로 돌아올 걸 확신한다면 빠른 업그레이드 재부팅이 가능하다.
- 그렇지만 5분 후에 다시 온라인 상태가 될지는 확신할 수 없다.
- 확신할 수 없으니 더 안전한 방법을 선택해야한다.
- 작업이 클러스터 내 다른 노드로 이동하도록 모든 노드의 파드를 의도적으로 drain하는 방법이다. 엄밀히 말하면 그대로 옮기는 것은 아니다.
- 한 노드를 drain하면 해당 노드에서 파드가 정상적으로 종료되고 다른 노드에 재현된다.
- 노드는 또한 drain 이후에는 cordoned 되거나 unschedulable 상태로 변경된다. 제한된 상태에서 벗어나기 전까지는 노드에서 파드를 스케줄링할 수 없다. 그래서 의도적으로 uncordon을 해주어야만 다시 파드를 스케줄링할 수 있다.
- 다른 노드로 옮겨진 파드가 자동으로 원래 있던 노드로 돌아가진 않는다. 다른 노드로 옮겨진 파드가 삭제되거나 클러스터에 새 파드가 생성되면 이 노드에서 생성될 것이다.
- cordon은 간단하게 노드에 unschedulable 상태로 마킹하는 것 뿐이다. drain과는 달리 기존 노드에서 파드를 종료하거나 이동시키지 않는다. 단순히 해당 노드에 새 파드가 스케줄링되지 않도록 하는 것이다.
kubectl cordon <node name>
kubectl uncordon <node name>
kubectl drain <node name>
Kubernetes Software Versions
- 쿠버네티스의 여러 버전과 release 버전에 대해 알아보자.
- 쿠버네티스 클러스터를 설치할 때 특정 버전의 쿠버네티스를 설치하게 된다.
- kubectl get node 명령을 실행하면 버전을 확인할 수 있다.
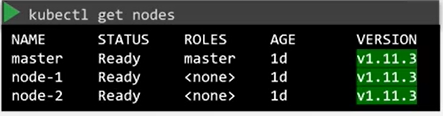
- 쿠버네티스는 소프트웨어 release를 어떻게 관리하는가?
- 버전 번호를 잘보면 VERSION은 <주 버전>.<마이너 버전>.<패치 버전> 세 부분으로 나뉜다.
- 새로운 기능과 기능을 갖춘 마이너 버전이 몇 달마다 출시되는 반면 중요한 버그 수정과 함께 패치가 더 자주 출시된다. 표준 소프트웨어 릴리스 버전 관리 절차를 따른다.
- 이 외에도 알파와 베타가 release 되기도 한다. 모든 버그를 고치고 개선하면 v1.10.0-alpha와 같이 먼저 알파 태그를 부착한 알파 버전을 release한다. 이 릴리스에선 기본값으로 기능이 비활성화 돼 버그가 있을 수도 있다.
- 그런 다음 v1.10.0-beta 와 같이 베타 릴리스 버전으로 넘어간다. 테스트가 완료되면 새 기능이 디폴트로 활성화된다.
- 쿠버네티스 Github 리포지토리의 release 페이지에서 모든 release를 찾을 수 있다.
- https://github.com/kubernetes/kubernetes/releases
Cluster Upgrade Process
- 쿠버네티스 소프트웨어는 구성 요소마다 버전이 다르다. 예를들어 Etcd, CoreDNS 등등
- 꼭 모두 같은 버전을 가질수는 없다. 다른 프로젝트로 운영되는 서비스들이 많기 때문에
- kube-apiserver는 컨트롤 플레인의 주요 구성요소이고 다른 구성요소들과 통신하는 구성요소라서 어떤 다른 구성요소도 kube-apiserver보다 높은 버전이어서는 안된다.

- 위와같은 공식으로 이해를 하고 있으면 된다.
- kube-apisetver는 가장 높은 버전 X라고 가정
- kube-scheduler ,Controller-manager의 경우 X-1 까지 가능
- kubelet, kube-proxy 의 경우 X-2 까지 가능
- kubectl은 예외로 X+1 과 X-1 사이에 있기만 하면 된다.
(kube-apiserver가 1.10 버전인 경우 1.11, 1.10, 1.9의 경우의 수가 생기는 것) - 위 편차가 허용되는 버전으로 실시간 업그레이드를 할 수 있다.
- 그렇다면 업그레이드를 어떻게 하는가? 1.10 에서 1.13으로 바로 업그레이드 해도 되는가?
- 업그레이드는 한 번에 마이너 버전 하나 씩 업그레이드하는 걸 권장한다. 1.10 -> 1.11 -> 1.12 이런 방식으로
- 업그레이드 프로세스는 클러스터 설정에 달려있다. 예를 들어 구글 클라우드 쿠버네티스 엔진은 클러스터를 쉽게 업그레이드하게 해준다.
- 만약 클러스터를 처음부터 배포했다면 클러스터의 다양한 구성 요소를 직접 업그레이드 해야한다.
- 이번에는 kubeadm을 살펴보자
- 마스터와 워커 노드가 실행되는 운영망 파드에서 애플리케이션을 제공중이다. 노드와 구성 요소는 1.10 버전이다.
- 클러스터 업그레이드는 두 가지 주요 단계를 수반한다.
- 먼저 마스터 노드를 업그레이드
- 그 다음 워커 노드를 업그레이드
- 마스터 노드를 업그레이드 하는 동안 컨트롤 플레인의 구성요소 kube-apiserver, scheduler, controller manager와 같은 요소는 잠시 다운된다.
- kubectl이나 kube-apiserver를 이용해 클러스터에 액세스할 수 없어 새 애플리케이션을 배포하거나 기존 애플리케이션을 삭제, 수정할 수 없다.
- controller-manager도 작동을 안해 파드가 고장나면 새 파드가 자동으로 생성되지 않는다.
- 마스터가 다운된다고 클러스터 상의 워커 노드와 애플리케이션이 영향을 받는 건 아니다. 워커 노드에 호스트된 애플리케이션은 평소처럼 사용자를 돕게된다.
- 업그레이드가 완료되고 클러스터가 백업되면 정상적으로 작동하게 된다.
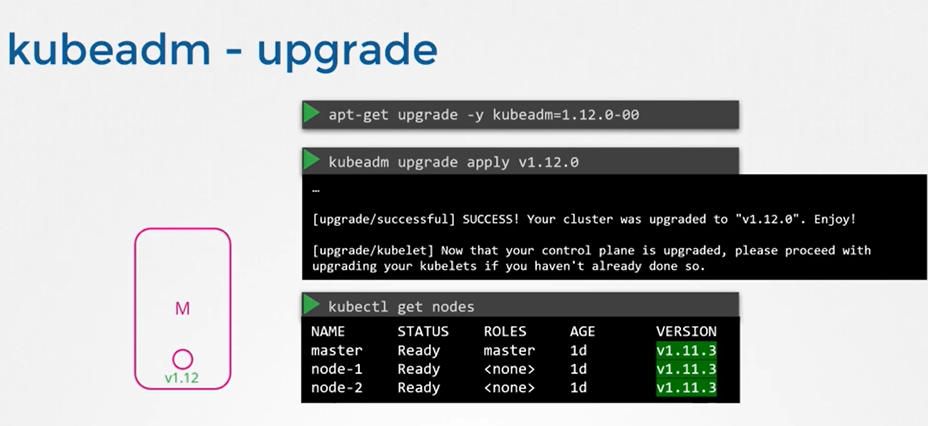
- 워커 노드 업그레이드는 다양한 업그레이드 전략이 있다.
- 하나는 한꺼번에 업그레이드
- 이 방법은 파드가 다운되면 사용자는 애플리케이션에 접속할 수 없다.
- 업그레이드가 완료될 때까지는 가동 중지가 되어 완료된 이후에 사용자가 다시 애플리케이션을 사용할 수 있다.
- 두 번째는 한 번에 하나씩 업그레이드
- 첫 번째 노드를 업그레이드 하면 노드 안에 있는 파드가 두 번째 세 번째 노드로 이동하고 사용자는 이동된 파드로 서비스된다.
- 첫 번째 노드가 업그레이드 되고 백업 되면 두 번째를 업그레이드한다.
- 이 처럼 단계별로 업그레이드 해서 가동 중지 시간을 없애는 것이다.
- 세 번째는 새로운 소프트웨어 버전을 가진 노드로 클러스터에 노드를 추가하는 것이다.
- 클라우드 환경에서 새 노드를 프로비전하고 오래된 것을 해체할 수 있어서 특히 편하다.
- 하나는 한꺼번에 업그레이드
kubeadm upgrade plan- 위 명령어를 사용하면 클러스터를 업그레이드할 수 있는지 확인하고 업그레이드할 수 있는 버전을 가져옵니다. 또한 구성 요소 구성 버전 상태가 포함된 테이블을 표시한다.
- 주의해야할 사항은 컨트롤 플레인 구성요소를 업그레이드 한 이후 반드시 수동으로 각각의 노드에 있는 kubelet을 업그레이드 해야한다. kubeadm 명령어는 kubelet의 업그레이드를 돕지 않기 때문이다.
- kubeadm을 사용하기 이전에 반드시 kubeadm 도구부터 업그레이드 해야한다. 물론 이것도 v1.11 -> v1.12 -> v1.13 단계적으로 업그레이드 해야한다.
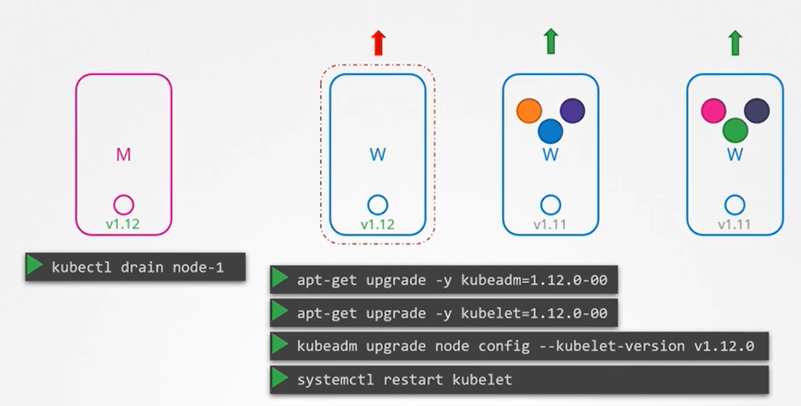
- kubelet을 업그레이드 하는 방법
- 보통 kubelet은 워커 노드에서 실행되지만 셋업에 따라 마스터 노드에서 kubelet이 실행될 수도 있다. 그래서 확인할 필요가 있다.
- kubeadm으로 배포된 클러스터는 마스터 노드에 kubelet이 있다.
- 마스터 노드에 kubelet이 있는 경우를 설명 해보자
apt-get upgrade kubelet- 패키지가 업그레이드 되면 kubelet 서비스를 다시 시작한다.
- kubectl get nodes 명령을 실행하면 마스터가 1.12로 업그레이드 됐음을 알 수 있다.
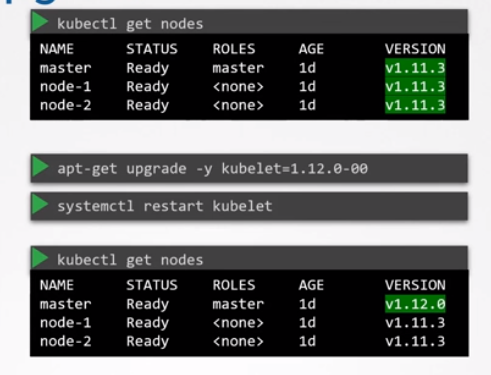
- 워커 노드는 여전히 1.11 버전이다.
- 이번엔 워커 노드를 업그레이드 할 차례다.
- 먼저 node-1에서 다른 노드로 워크로드를 이동해야 한다.
- kubectl drain 명령어를 사용하면 한 노드에서 모든 파드를 안전하게 종료하고 다시 스케줄링 할 수 있다.
- 다음 kubeadm upgrade 명령을 이용해서 새 kubelet 버전에 대한 노드 구성을 업데이트한다.

kubeadm upgrade node config --kubelet-version v1.12.0Backup and Restore Methods
과정이 조금 이상해서 다시 정리해야될 필요가 있음!
- 지금까지 쿠버네티스 클러스터에 디플로이먼트, 파드, 서비스 등 정의 파일을 이용해서 다양한 응용 프로그램을 배포했다.
- etcd는 모든 클러스터와 관련된 정보를 저장하고, 애플리케이션이 persistence volume 으로 구성된 경우 백업을 위한 또 다른 후보가 된다.
- 클러스터에서 생성한 리소스와 관련해 때로는 네임스페이스, Secret, ConfigMap 을 생성하거나 애플리케이션을 expose하는 등의 명령적 방법을 사용해 개체를 생성하기도 한다.
- 그리고 때로는 definition 파일을 생성한 다음 해당 파일을 apply 명령어를 수행하는 선언적 방법을 사용하기도 했다.
- 선언적 방법이 주로 선호되는 접근법이다.
- 단일 폴더에 definition 파일 형식으로 단일 애플리케이션에 필요한 모든 개체를 즉, 여러 개의 정의 파일을 구성하고 해당 구성을 저장하려면 이 방법이 좋다.
- 나중에 쉽게 재사용될 수 있고 다른 사람에게 공유될 수 있다.
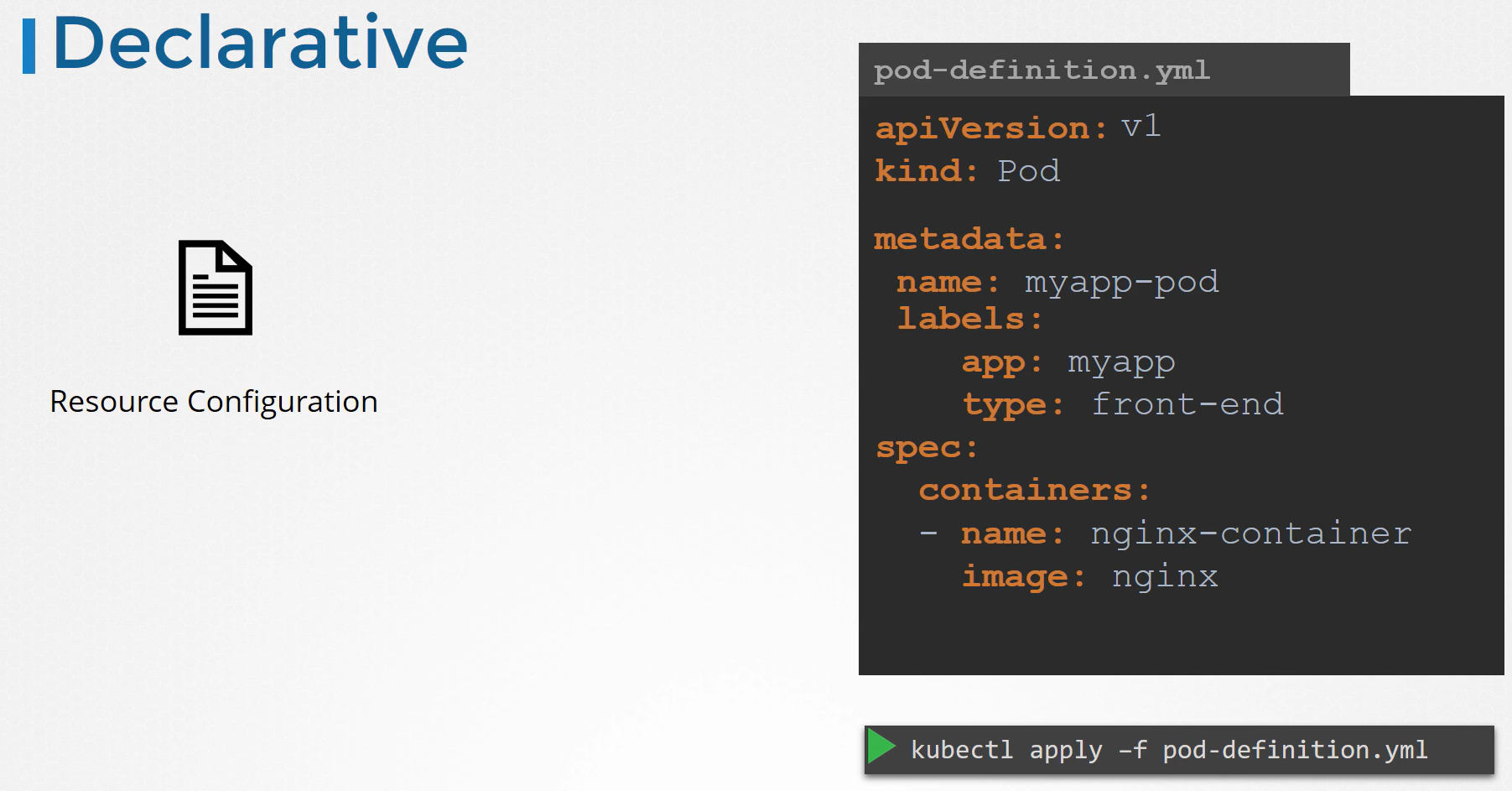
- 당연하게도 항상 이 모든 파일의 복사본을 가지고 있어야한다.
- 좋은 방법은 복사본들을 소스 코드 레포지토리에 저장하는 방법이다. 이 방법은 팀에서 유지관리 하기 쉽다.
- 소스 코드 레포지토리는 올바른 백업 솔루션으로 구성해야 한다. GitHub과 같은 소스 코드 저장소를 사용하면 이에 대해 걱정할 필요 없다.
- 이를 통해 전체 클러스터가 없어지더라도 구성 파일을 불러와 클러스터에 적용하기만 하면 애플리케이션을 다시 배포할 수 있다.
- 선언적 접근 방식이 선호되지만, 모든 팀원이 반드시 이러한 기준을 지킬 필요는 없다.
- 만약 누군가 정보를 어디에도 기록하지 않고 명령적인 방법으로 객체를 만든다면 어떤가? 이러한 경우 어디에서도 찾기 힘드니 자원에 대한 정보를 백업하는 더 나은 방법은 kube-apiserver 에 질의하는 것이다.
- kubectl을 사용하거나 api server에 직접 액세스해 kube API 서버에 쿼리하고 클러스터에 생성된 모든 개체에 대한 모든 리소스 구성을 복사본으로 저장한다.
- 예를 들어 백업 스크립트에서 사용할 수 있는 명령 중 하나는 kubectl 의 get all 명령을 사용해 모든 파드, 디플로이먼트, 네임스페이스의 서비스를 가져온 다음 출력을 YAML 형식으로 추출해 해당 파일을 저장하는 것이다.

- 그리고 이것은 몇 개의 리소스 그룹을 위한 것이며, 다른 고려해야 할 리소스 그룹이 많이 있다. 이런 솔루션들은 Ark 또는 Velero(Heptio의) 같은 도구가 있다. 이 도구들은 쿠버네티스 API를 사용해 클러스터의 백업을 수행하는 데 도움을 줄 수 있다.
- etcd 클러스터에는 클러스터의 상태에 대한 정보가 저장되어 있다. 클러스터 자체, 노드 및 클러스터 내에서 생성된 모든 리소스에 대한 정보가 여기에 저장된다.
- 그래서 리소스를 백업하는 대신 etcd 서버 자체를 백업하는 방법을 선택할 수도 있다. 앞서 본 것처럼 etcd 클러스터는 마스터 노드에서 호스팅되며 etcd를 구성할 때 모든 데이터를 저장할 위치인 data 디렉터리를 지정했다. 백업 도구에서 백업하도록 구성할 수 있는 디렉터리이다.
- Etcd는 스냅샷 솔루션이 내장되어 있다. etcdctl 명령어의 snapshot save 명령어를 사용하면 etcd 데이터베이스의 스냅샷을 만들 수 있다.
- 다른 위치에 생성하려면 전체 경로를 지정해야한다.
- snapshot status 명령을 사용해서 백업 상태를 볼수 있다.
etcdctl snapshot save <snapshot path,name>
etcdctl snapshot status <snapshot path,name>

- 나중에 백업에서 클러스터를 복원하려면 먼저 kube api server 서비스를 중지해야 한다.
service kube-apiserver stop- kube api server가 종속되어 있기 때문에 복원 프로세스를 수행하려면 etcd 클러스터를 다시 시작해야한다.
- 그 다음 백업 파일의 경로인 snapshot.db 파일로 설정된 경로를 사용해 명령어를 입력한다.
etcdctl snapshot restore --data-dir /var/lib/etcd-from-backup- etcd가 백업에서 복원할 경우 새 클러스터 구성을 초기화하고 etcd의 새로운 멤버로 구성한다.
- 새 멤버가 실수로 기존의 클러스터에 합류하는 것을 막기 위해서다.
- 그 다음 새로운 데이터 디렉터리를 사용하도록 etcd configuration 파일을 구성한다.

- 그 다음 systemctl daemon-reload 명령어와 service etcd restart 명령어를 이용해서 etcd 서비스 데몬을 다시 재기동한다.
- 마지막으로 service kube-apiserver start 명령어로 kube api server 서비스를 시작한다. 클러스터는 원래 상태로 돌아가야한다.

- 또한 엔드포인트와 함께 서버 인증서 파일을 지정해야한다.
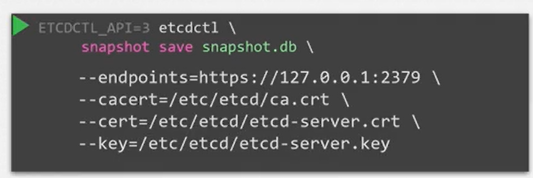
- 백업을 위한 방법은 두 가지가 있다. etcdctl을 이용한 방법과 kube api server 쿼리를 통한 백업이다.
- Managed 쿠버네티스 환경을 사용하는 경우 etcd 클러스터로 접근하지 않을 수도 있다.
- 이 경우 kube api 서버로 쿼리를 날려 백업하는 게 더 좋은 방법일 것이다.
etcdctl 사용하기
- etcdctl은 etcd의 명령줄 클라이언트이다.
- 모든 쿠버네티스 실습(kudekloud)에서 etcd 키-값 데이터베이스는 마스터에 정적 파드로 배포되며, 버전은 v3이다.
- 백업 및 복원과 같은 작업에 etcdctl을 사용하려면 ETCDCTL_API를 3으로 설정해야 한다.
- export ETCDCTL_API=3를 이용해서 서버 내부에 설정해주어야 한다.
- 스냅샷을 생성하려면 etcdctl snapshot save -h를 실행하고 필수 글로벌 옵션을 메모해두는게 좋다. 대표적으로 아래와 같다.
- --cacert : CA 번들을 사용해 TLS 사용 보안 서버의 인증서를 확인한다.
- --cert : TLS 인증서 파일을 사용하여 보안 클라이언트 식별
- --endpoints=[127.0.0.1:2379] : etcd는 마스터 노드에서 실행되고 로컬 호스트 2379에 노출되므로 기본값이다.
- --key : TLS 키 파일을 사용해 보안 클라이언트 식별
- 마찬가지로 ectdctl snapshot restore -h 를 실행해 자세한 설명을 참조하는 것이 좋다.
시험 꿀팁!
- 시험에서는 이 백업 복구하는 과정이 자신이 한 일이 정확한지 아닌지 알 수 없다. 자신의 작업을 직접 확인해야 한다.
-> 무슨 말이지..? - 예를 들어 특정 이미지로 파드를 만드는 문제라면 kubectl describe pod 를 실행해 파드가 올바른 이름과 올바른 이미지로 만들어졌는지 확인해야 한다.
음... 아직 Practice 문제를 안풀어봐서 그런지 개념적인 부분은 이해가 갔으나 직접 해봐야 알듯하다. etcd api로 직접 명령어를 날리는 부분이 조금 어렵고 백업 및 복원을 하는 과정을 다시 한번 정리 해봐야겠다.
반응형
'자격증 > Kubernetes CKA' 카테고리의 다른 글
| [CKA] Security - 2 (0) | 2023.12.13 |
|---|---|
| [CKA] Security - 1 (0) | 2023.12.12 |
| [CKA] Practice Test - Rolling Updates And Rollbacks (0) | 2023.12.03 |
| [CKA] Application Lifecycle Management (0) | 2023.12.03 |
| [CKA] Practice Test - Monitor Cluster Components, Managing Application Logs (0) | 2023.12.03 |