
반응형

Pod Networking
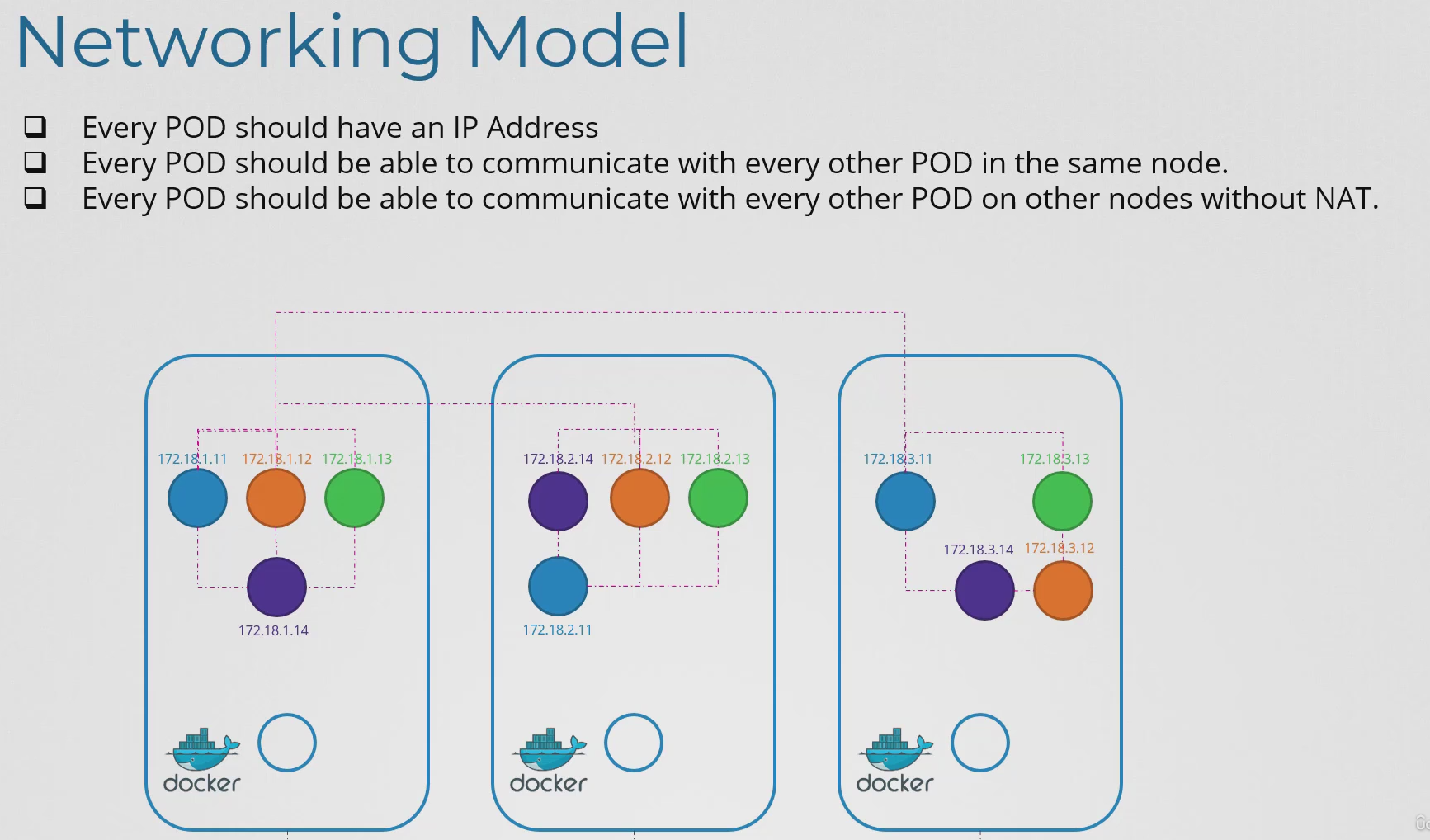
- 파드 레이어의 네트워킹은 어떻게 되는가?
- 클러스터에는 많은 파드가 실행될 것이다.
- 파드는 어떻게 주소 지정되는지, 서로 어떻게 통신하는 지 클러스터 내에서 이러한 파드에서 실행되는 서비스에 어떻게 접근하는지? 그리고 클러스터 외부에서 어떻게 접근하는 지 등이 고려해야할 문제이다.
- 쿠버네티스는 현재로서는 이러한 문제들에 대해서 내장 솔루션을 제공하지 않는다. 그래서 이런 문제들을 해결하기 위한 네트워킹 솔루션을 구현해야한다.
- 위 이미지를 보면 쿠버네티스가 파드 네트워킹에 대한 요구사항을 제시했다.
- 각 파드가 고유한 IP 주소를 가져야한다.
- 각 파드는 해당 IP 주소를 사용해 동일한 노드 내의 다른 모든 파드에 도달할 수 있어야한다.
- 각 파드는 동일한 IP 주소를 사용해 다른 노드의 다른 모든 파드에도 도달할 수 있어야한다.
- 단순히 어떤 IP 주소인지, 어떤 범위나 서브넷에 속하는지는 중요하지 않다. 자동으로 IP 주소를 할당하고 노드 내의 파드 및 다른 노드의 파드 간에 연결을 설정하는 솔루션을 구현할 수 있다면 된다.
- 현재 weave, flannel, cilium 등등 많은 네트워킹 솔루션이 위와 같은 기능을 제공한다.
- 그러나 우리는 이미 네트워킹, 라우팅, IP 주소 관리, 네임스페이스 및 CNI에 대해 배웠기 때문에 이 지식을 활용해 문제를 해결해 보도록 한다. 자체적으로 해결하려고 노력하는 것은 다른 솔루션이 어떻게 작동하는지 이해하는 데 도움이 될 것이다.
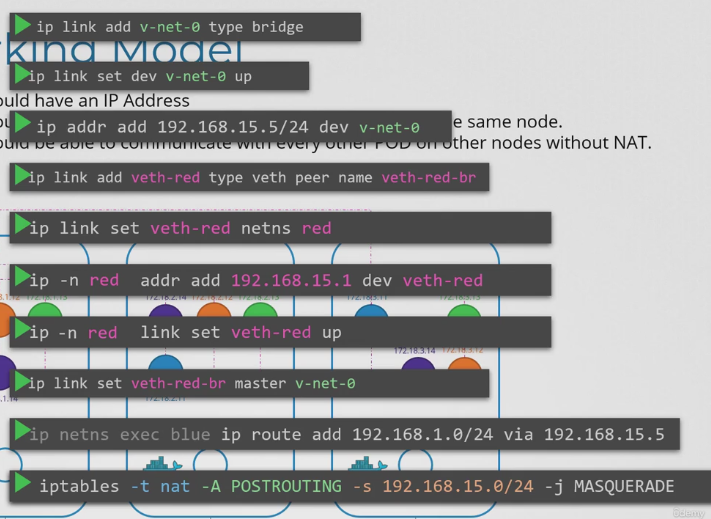

- 먼저 위와 같은 구성을 한다고 가정한다. 세 개의 노드 클러스터가 있고, 모두 관리 또는 워크로드 목적으로 파드를 실행한다.
- 어느 것이 마스터이고 어느 것이 워커 노드인지는 중요하지 않고 네트워킹 관점에서는 모두 동일한 것으로 간주한다.
- 노드는 외부 네트워크의 일부이며 192.168.1 의 IP 주소를 가지고 있다. 노드 1은 11, 노드 2는 12, 노드 3은 13으로 할당되어 있다.
- 컨테이너가 생성되면 쿠버네티스는 컨테이너를 위해 네트워크 네임스페이스를 생성한다. 컨테이너 간의 통신을 가능하게 하기 위해 이 네임스페이스를 어떤 네트워크에 연결할 것인지 생각한다.
- 그래서 우리는 각 노드에 브릿지 네트워크를 생성한다. 브릿지 네트워크는 고유한 서브넷이 있을 것이고, 192.168.1 과같은 대역이 아니라 10.240.1.0와 10.240.2.0 와 같은 별도의 사설 대역으로 구성된다.
- 나머지는 컨테이너가 생성될 때마다 네트워크에 연결해야한다. 각 컨테이너가 생성될 때마다 스크립트를 실행 해준다.
- ip addr 명령을 사용해 ip 주소를 할당하고 기본 게이트웨이에 대한 라우팅을 추가한다. 그러나 어떤 IP를 추가해야할까? 직접 관리하거나 해당 정보를 어떤 종류의 DB에 저장한다.
- 지금은 서브넷에 있는 10.244.1.2 라고 가정해보자
- 마지막으로 인터페이스를 Run 시키고, 스크립트를 두 번째 컨테이너에 실행해 A와 B 컨테이너에 통신이 되는 지 확인해보면 된다. 확인 시 통신이 잘 될것이다.
- 스크립트를 다른 노드로 복사하고 해당 스크립트를 실행해서 IP 주소를 사용해 동일한 노드 내의 다른 모든 파드에 도달할 수있어야 한다는 요구 사항을 해결할 수 있다.
- 두 번째로는 다른 노드의 다른 파드에 도달할 수 있도록 하는 것이다.
- 노드 1의 10.244.1.2 파드가 노드 2의 10.244.2.2 파드를 핑하려면 어떻게 해야하는가?
- 일단 노드 1은 노드 2를 모르기 때문에 기본 게이트웨이로 노드 1의 IP로 라우팅하고 노드 1의 라우팅 테이블에 10.244.2.2로 트래픽을 라우팅하기 위한 경로를 추가하면 된다.
- 근데 이 방법은 간단한 설정에서는 상관없지만 네트워크 아키텍처가 복잡해지면 더 많은 구성이 필요할 것이다.
- 모든 서버에 경로를 구성하는 대신, 네트워크에 라우터가 있다면 라우터에서 이 작업을 수행하고 모든 호스트가 해당 라우터를 기본 게이트웨이로 사용하도록 하는 것이 더 나은 해결책이다.
- 또 우리는 스크립트를 수동으로 실행했다. 대규모 환경에서 스크립트를 수동으로 실행할 수 있을까? 그렇다면 파드가 생성될 때 스크립트를 자동으로 실행하는 방법은 무엇일까?
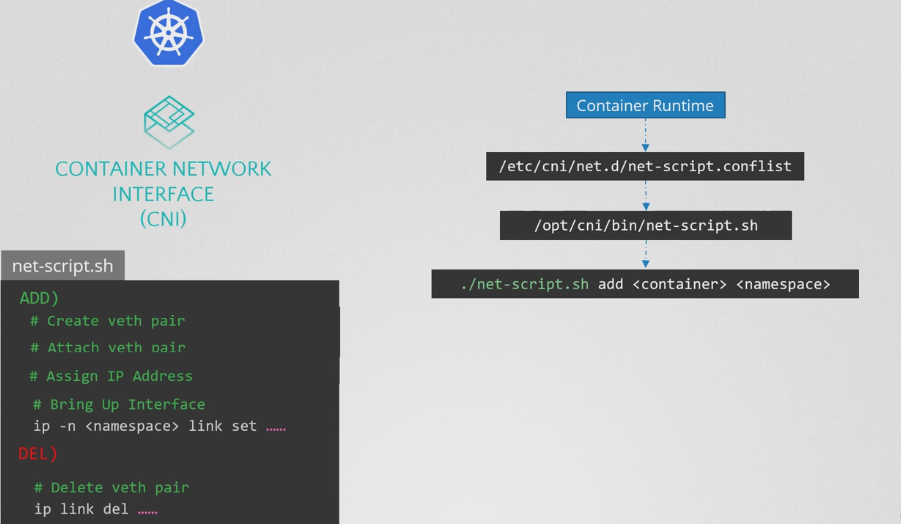
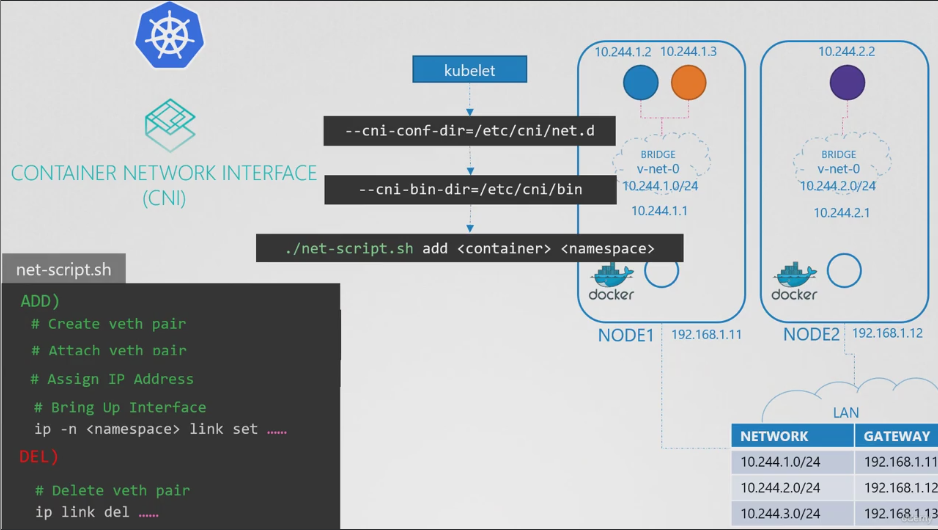
- 여기에서 CNI가 사용된다. CNI는 쿠버네티스에게 컨테이너를 생성하자마자 스크립트를 호출하라고 알려주고 CNI는 스크립트를 정의해놓고 알려준다. 따라서 CNI 표준을 충족하도록 위에서 사용한 스크립트를 약간 수정해야한다.
- 컨테이너가 생성될 때 컨테이너 런타임은 실행될 때 전달된 CNI 구성을 확인하고 스크립트의 이름을 식별한다.
- 그런다음 해당 CNI의 bin 디렉터리에서 스크립트를 찾아 add 명령 및 컨테이너의 이름 및 네임스페이스 ID와 함께 스크립트를 실행하고 나머지는 우리 스크립트가 처리한다.
CNI in kubernetes

- CNI는 컨테이너 런타임의 책임을 정의하며 CNI 컨테이너 런타임에 따라 다르다.
- 쿠버네티스는 컨테이너 네트워크 네임스페이스를 생성하고 해당 네임스페이스를 올바른 네트워크에 식별하여 올바른 네트워크 플러그인을 호출해야한다.
- 그렇다면 쿠버네티스에서 CNI 플러그인을 어디에 지정해야 하는가?

- CNI 플러그인은 클러스터의 각 노드에서 kubelet.service 파일에 --network-plugin-cni 옵션이 있다.
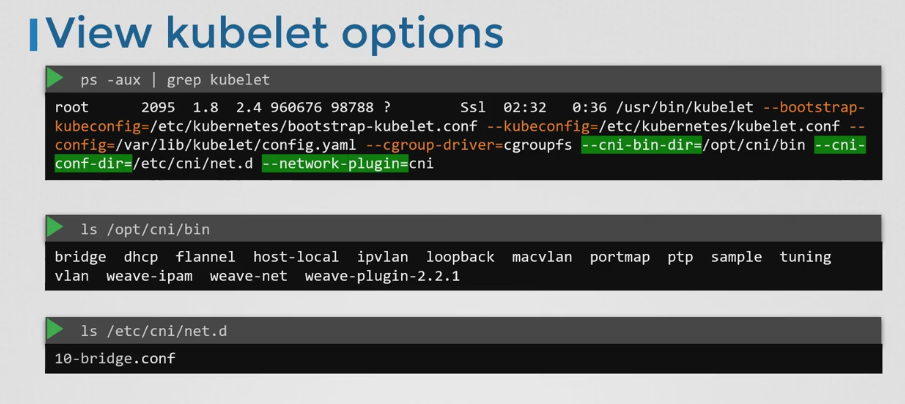
- 이는 ps -aux 명령어를 사용해 실행 중인 kubelet을 검색해보면 환경 설정을 확인 가능하다.
- /opt/cni/bin 디렉터리에는 dhcp, flannel 등 모든 지원되는 CNI 플러그인이 실행파일로 들어있다.
- --cni-conf-dir 옵션에서는 구성 파일 세트를 확인할 수 있다. kubelet은 여기에서 어떤 플러그인을 사용해야 하는지 알아내기 위해 브릿지 구성 파일을 찾는다. 여러 파일이 있는 경우 알파벳 순서로 선택된다.

- 브릿지 구성 파일은 다음과 같다.
- CNI 표준에 따라 정의된 플러그인 구성 파일 형식이다. 브릿지, 라우팅, Masquerading 등이 있다.
- isGateway 는 브릿지 네트워크에 IP 주소를 할당해 게이트웨이로 작동해야 한느지를 정의한다.
- ipMasq는 IP Masquerading을 위한 NAT 규칙을 추가해야 하는지를 정의한다.
- IPAM 섹션은 IPAM 구성을 정의한다. 여기에는 파드에 할당될 IP 주소의 서브넷이나 법위와 필요한 모든 로드를 지정한다.
- type : host-local 은 IP 주소가 이 호스트에서 로컬로 관리된다는 것을 나타낸다. DHCP 서버와 달리 원격으로 유지하지 않는다. type은 외부 DHCP 서버를 구성하기 위해 DHCP로 설정할 수도 있다.
CNI weave
- CNI 플러그인인 weaveworks에 대해 알아보자
- 지난 번 강의에서 봤듯이 CNI 스크립트를 이용해 네트워크 설정을 했었는데, 자체 사용자 정의 스크립트가 아니라 weave 플로그인을 통합하는 방법을 알아보도록하자.
- 수동으로 설정한 네트워킹 솔루션은 라우팅 테이블이 구성되어 있었다.
- 간단한 네트워크에서는 문제가 없으나 수백 개의 노드와 각 노드 별로 여러 개의 pod가 있는 큰 환경에서는 실용적이지 않다.
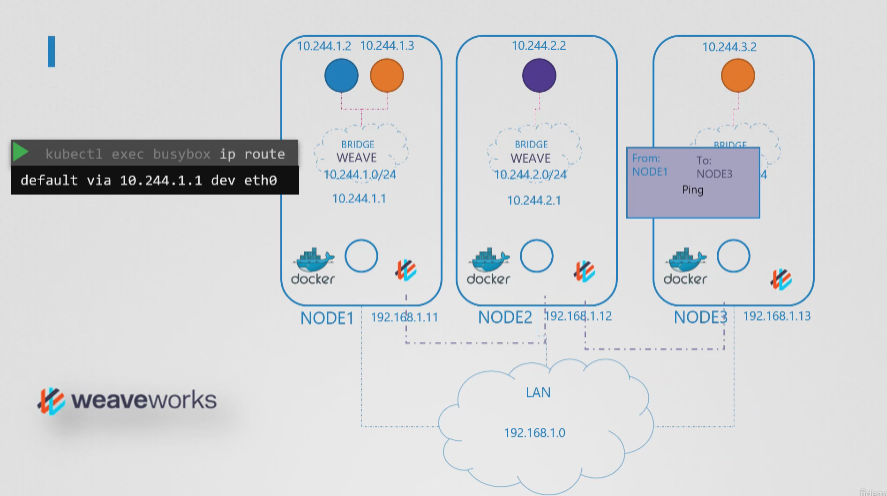
- 한 노드에서 다른 노드로 패킷을 보낼 때 Weave는 패킷을 가로채어 별도의 네트워크에 있다는 것을 식별하고 이를 새로운 출발지와 목적지가 설정된 새로운 패킷으로 캡슐화하고 네트워크를 통해 보냅니다.
- Weave CNI 플러그인이 클러스터에 배포된 경우, 각 노드에 에이전트 또는 서비스를 배포한다. 이들은 서로 통신하여 노드 및 네트워크에 관한 정보를 교환한다.
- 각 에이전트 또는 피어는 전체 설정의 일부를 저장하여 다른 노드의 팟과 해당 IP를 알고 있다.
- Weave는 노드 및 이름에 자체 브릿지를 만들고 IP 주소를 각 네트워크에 할당한다.
- 파드는 단일 브리지 네트워크에 속하는 것이 아니라 여러 브리지 네트워크에 연결될 수 있다.
- 패킷이 목적지에 도달하려면 컨테이너에 구성된 경로에 따라 간다. 우리는 파드가 에이전트에 도달하도록 올바른 경로가 구성되었음을 확인했고, 에이전트가 다른 파드를 처리한다.
- 이제 한 노드에서 다른 노드로 패킷을 보낼 때 Weave는 패킷을 가로채어 별도의 네트워크에 있다는 것을 식별하고 이를 새로운 출발지와 목적지가 설정된 새로운 패킷으로 캡슐화하고 네트워크를 통해 보낸다.
- 반대편에 도착하면 다른 Weave 에이전트가 패킷을 검색하고 캡슐화를 해제하고 패킷을 올바른 팟으로 라우팅한다.
weave 배포 방법
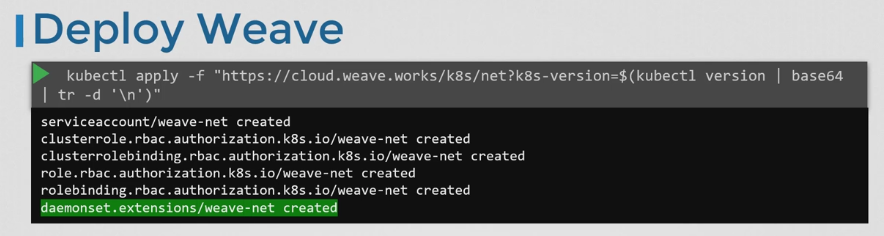
- weave 및 weave peer는 각 노드에 서비스 또는 데몬으로 수동으로 배포되거나 이미 쿠버네티스가 설정된 경우 클러스터의 파드로 배포하는 더 쉬운 방법이 있다.
- 기본 쿠버네티스 시스템이 노드와 노드 간에 올바르게 구성된 네트워킹을 사용하고 컨트롤 플레인 구성요소가 배포된 경우 weave는 클러스터에 kubectl apply 명령으로 배포될 수 있다.
- 중요한 것은 weave peer가 daemonset 으로 배포된다는 것이다.

- kubeadm 과 weave 플러그인으로 클러스터를 배포한 경우 kubectl logs 명령을 사용해 각 노드에 배포된 weave 피어를 볼 수 있다.
IP Address Management - Weave
- 쿠버네티스에서 IP 주소 관리는 어떻게 작동할까?
- 우리가 직접 하거나 IPAM 솔루션과 함께 관리할 수 있다.
- 이 섹션에서는 노드의 가상 브릿지 네트워크가 어떻게 IP 서브넷으로 할당되며 파드가 어떻게 IP를 할당 받는지, 이 정보가 어디에 저장되며 중복된 IP가 할당되지 않도록 누가 책임 지는지이다.
- CNI에 따르면 IP 할당은 컨테이너에 IP를 할당하는 CNI 플러그인 또는 네트워크 솔루션 제공 업체의 책임이다.
- 이전에 만들었던 기본 플러그인에서는 실제로 IP 주소 할당에 관해 신경썼다. 컨테이너 네트워크 네임스페이스에 IP를 할당하는 섹션이 있었다.
- 그렇다면 이러한 IP를 어떻게 관리해야하는가?
- 쿠버네티스는 어떻게 하는 지 신경쓰지 않는다. 다만 중복 IP를 할당하지 않도록 주의하고 제대로 관리하기만 하면 된다.
- 이를 수행하는 간단한 방법은 IP 목록을 파일에 저장하고 이 파일을 스크립트에서 제대로 관리할 수 있도록 필요한 코드를 갖추는 것이다.
- 이 파일은 각 호스트에 배치되어 해당 노드의 파드의 IP를 관리한다.
- 스크립트에서 이를 직접 코딩하는 대신 CNI는 이 작업을 외부로 위탁할 수 있는 두 가지 내장 플러그인을 제공한다.
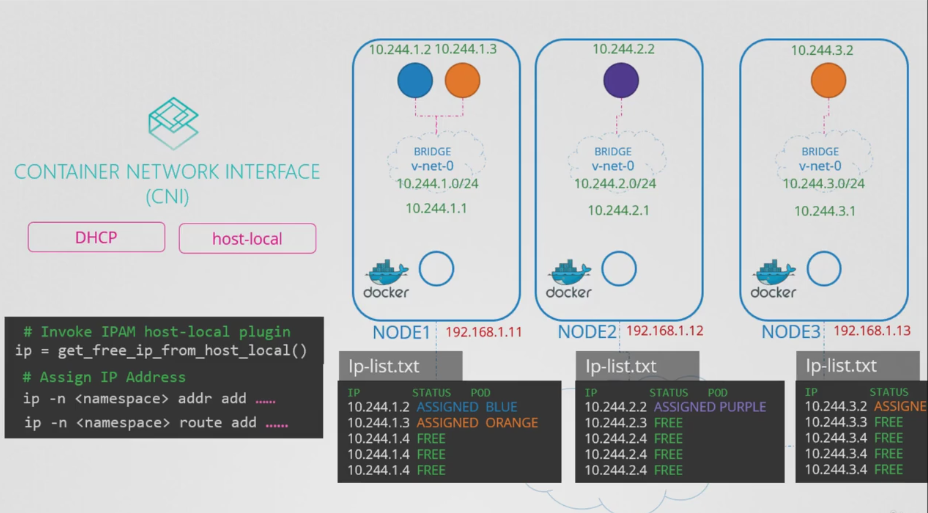
- 여기서 IP 주소를 각 호스트에서 로컬로 관리하는 접근 방식을 구현하는 플러그인은 호스트 로컬 플러그인이다.
- 그러나 여전히 스크립트에서 이 플러그인을 호출하는 것은 우리의 책임이며, 또한 스크립트를 동적으로 만들어 다양한 종류의 플러그인을 지원할 수도 있다.

- CNI 구성 파일에는 사용할 플러그인 유형, 사용할 서브넷 및 라우팅을 지정할 수있는 IPAM이라는 섹션이 있다.
- 이러한 세부 정보는 매번 호스트 로컬을 사용하도록 하드코딩하는 대신에 적절한 플러그인을 호출하기 위해 스크립트에서 읽어와 각기 다른 플러그인을 호출하는 데 사용될 수 있다.
- 이런 세부 정보는 네트워크 솔루션 공급자마다 다르다.
- weaveworks가 IP 주소를 어떻게 관리하는지 살펴보자
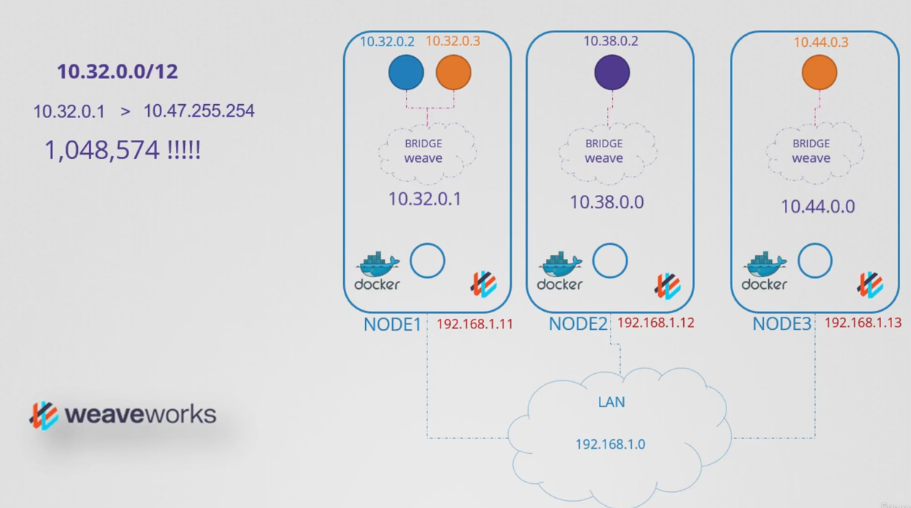
- weave는 기본적으로 전체 네트워크에 대해 10.32.0.0/12 를 할당한다.
- 이는 10.32.0.1 ~ 10.47.255.254 의 범위를 갖는 것과 같다.
- 이 범위에서 피어는 IP 주소를 균등하게 분할하고 각 노드에 하나씩 할당한다. 이러한 노드에서 생성된 파드는 이 범위 내의 IP를 갖는다. 물론 이러한 범위는 weave 플러그인을 클러스터에 배포할 때 추가 옵션으로 구성할 수 있다.
Service Networking
- 이번에는 서비스 네트워킹에 대해 얘기 해보자
- 이전 강의에서는 어떻게 각 노드 내에서 브릿지 네트워크가 생성되며, 파드가 생성된 네임스페이스, 해당 네임스페이스에 인터페이스가 연결되는 방법, 해당 노드에 할당된 서브넷 내에서 파드가 할당된 IP 주소를 얻는 방법을 설명했다.
- 라우팅이나 기타 오버레이 기술을 통해 다른 노드의 파드가 서로 통신하도록 할 수 있으며, 모든 파드가 서로에게 도달할 수 있는 큰 가상 네트워크를 형성할 수 있다는 것을 보았다.
- 다른 파드에서 호스팅 된 서비스에 액세스하려면 항상 서비스를 사용한다. 직접적으로 파드를 통신하도록 구성하지 않을 것이다.
- 서비스를 이용하면 서비스의 IP 또는 이름을 통해 파드에 액세스할 수 있다. 그것이 다른 노드에 속해 있던 상관없이 파드가 노드에서 호스팅 되는 동안 서비스는 클러스터 전체에 걸쳐 호스팅된다.
- 특정 노드에 바인드되지 않지만 기억해야 할 점은 서비스는 클러스터 내에서만 접근 가능하다는 것이다. 이 유형의 서비스를 ClusterIP라고 한다.
- 클러스터 외부에서 해당 파드의 응용 프로그램에 액세스하려면 NodePort 유형의 다른 서비스를 만들어야한다. 이 서비스에도 IP 주소가 할당되며, ClusterIP와 마찬가지로 다른 모든 파드는 이 서비스에 대한 IP를 사용하여 액세스할 수 있다.
- 그러나 추가로 해당 서비스를 클러스터의 모든 노드의 포트를 통해 응용 프로그램을 노출한다. 이렇게하면 외부 사용자 또는 응용 프로그램이 서비스에 액세스할 수 있다.
- 서비스가 이러한 IP 주소를 어떻게 얻고 클러스터의 모든 노드에서 사용할 수 있게 하는지, 서비스를 어떻게 클러스터 내부에서 외부 사용자에게 포트를 통해 제공하고 있는지에 대해 얘기할 것이다.
- 여기까지는 서론이다.
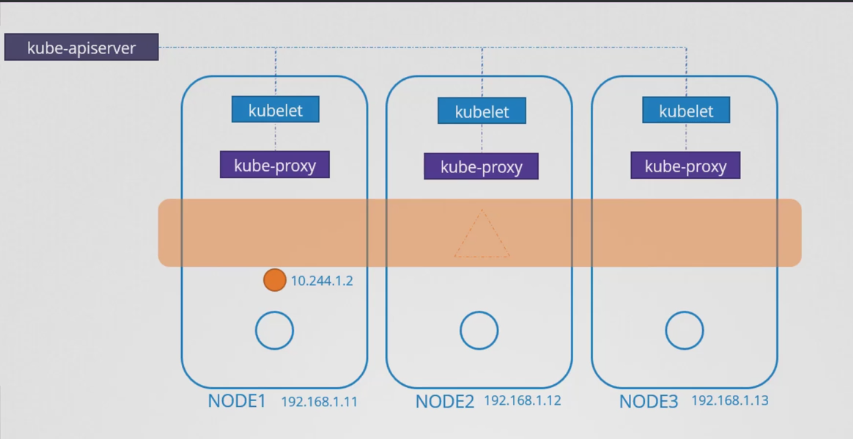
- 파드나 서비스가 없는 세 대의 노드 클러스터가 있다.
- 모든 쿠버네티스 노드는 파드를 생성하는 kubelet 프로세스를 실행한다.
- 각 노드의 kubelet 서비스는 kube-apiserver를 통해 클러스터의 변경 사항을 감시하고 새로운 파드를 생성해야할 때마다 노드에서 파드를 생성한다. 그 다음 CNI 플러그인을 호출해 해당 파드에 대한 네트워킹을 구성한다.
- 또한 각 노드는 kube-proxy라는 다른 구성 요소를 실행ㅎ나다. kube-proxy는 kube-apiserver를 통해 클러스터의 변경 사항을 감시하고 새로운 서비스를 생성해야 할 때마다 kube-proxy가 작동한다.
- 서비스는 클러스터 전반의 개념이라 각 노드에 속하지 않는다. 모든 노드에 걸쳐 존재한다.
- 사실은 서비스는 전혀 존재하지 않는다. 실제로 서비스 IP에서 수신되는 서버나 서비스는 없다.
- 우리는 파드가 컨테이너를 가지고 있고, 컨테이너에는 인터페이스와 그 인터페이스에 할당된 IP가 있다는 것을 보았다. 서비스에는 그와 같은 것이 전혀 없다.
- 또 서비스를 위한 프로세스나 네임스페이스, 또는 인터페이스는 없다. 단지 가상의 객체일 뿐이다.
- 그렇다면 어떻게 서비스가 IP 주소를 얻고 파드를 통해 응용 프로그램에 액세스할 수 있는 것일까?
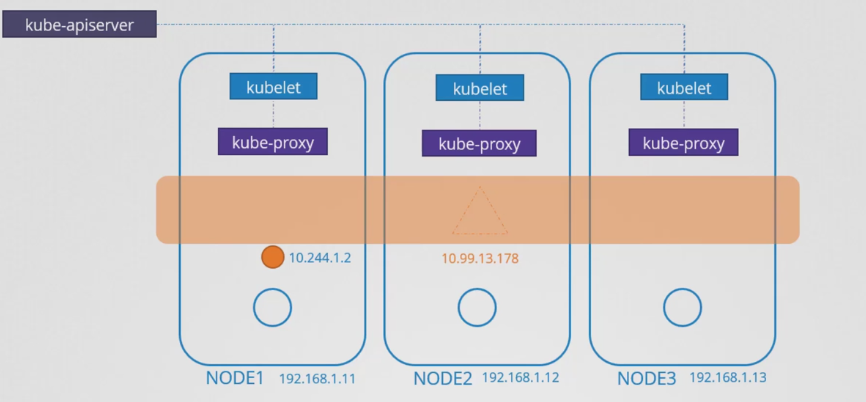
- 쿠버네티스에서 서비스 객체를 생성하면 미리 정의된 범위에서 IP 주소가 할당된다. 각 노드에서 실행되는 kube-proxy 구성 요소는 해당 IP 주소를 가져와 클러스터 내 각 노드에서 전달 규칙을 만든다.
- 이는 "이 IP로 오는 모든 트래픽은 파드의 IP로 이동해야한다"라고 말하는 것과 같다.
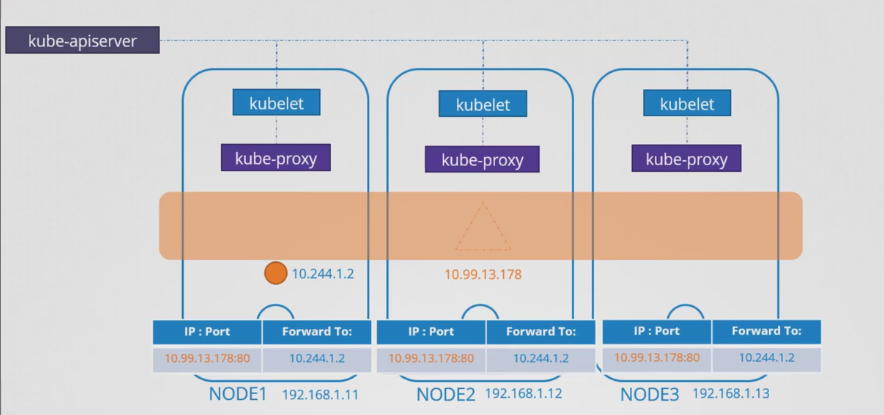
- 이것이 마련되면 파드가 서비스의 IP 주소에 액세스하려고 할 때 해당 파드의 IP 주소로 전달되며 클러스터의 모든 노드에서 액세스할 수 있게 된다.
- 이는 단순히 IP 뿐만 아니라 IP 및 포트 조합이다.
- 서비스가 생성되거나 삭제될 때마다 kube-proxy 구성 요소는 이러한 규칙을 생성하거나 삭제한다.
- 그렇다면 이러한 규칙은 어떻게 생성되는 것인가?
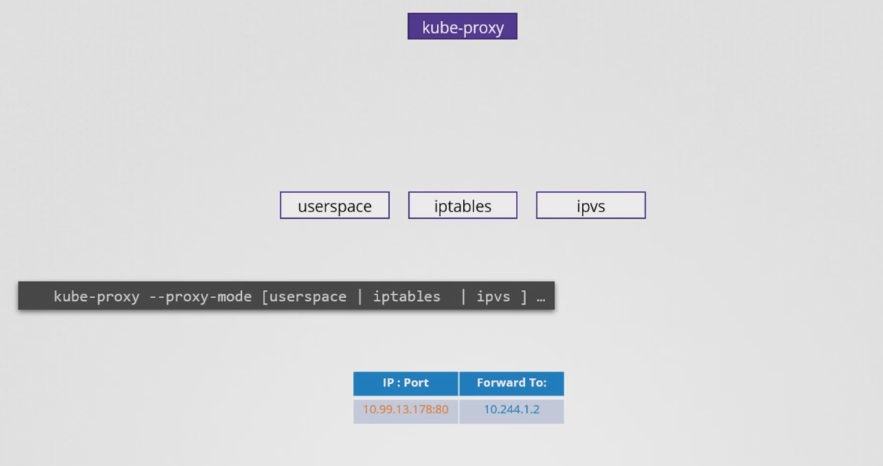
- kube-proxy는 userspace, iptables, ipvs를 통해 이러한 규칙을 마련한다.
- userspace에서 kube-proxy가 각 서비스에 대해 포트를 리스닝하고 ipvs 규칙을 만들어 연결을 프록시하도록 하는 userspace가 있다.
- 또한 iptables를 사용할 수 있다.
- --proxy-mode 옵션은 kube-proxy 서비스를 구성할 때 설정할 수 있다. 이 옵션이 설정되지 않으면 기본적으로 iptables로 설정된다.
- 그래서 iptables가 kube-proxy에 의해 어떻게 구성되는지, 그리고 노드에서 어떻게 볼 수 있는지 살펴보자.
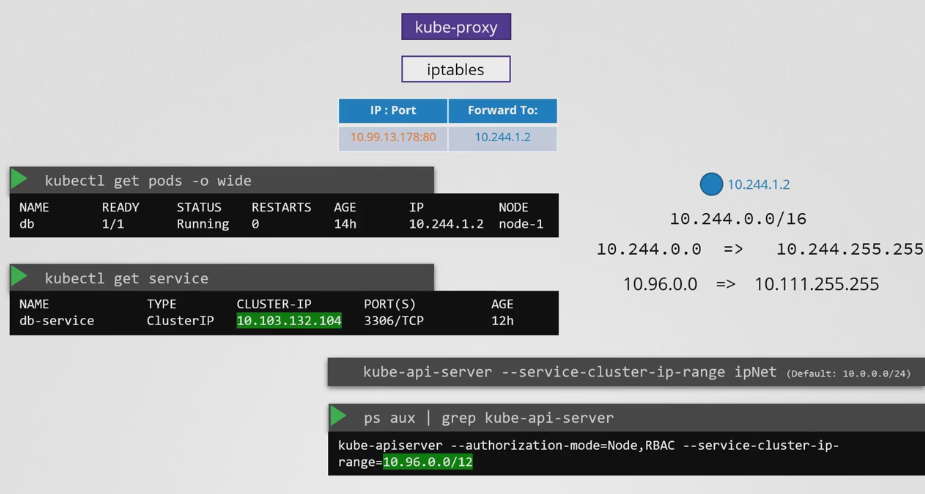
- 노드 1 에 db 라는 이름의 파드가 배포되어 있다고 가정해보자. 이 파드는 10.244.1.2를 갖는다. 이 파드를 클러스터 내에서 사용 가능하게 만들기 위해 해당 클러스터 IP의 서비스를 생성한다.
- 서비스가 생성되면 쿠버네티스는 서비스에 IP 주소를 할당한다. 10.103.132.104로 설정된다.
- 이 범위는 기본적으로 10.0.0.0/24로 설정된 kube-apiserver의 옵션인 --service-cluster-ip-range에 지정된다.
- ps aux | grep 으로 확인해보면 10.96.0.0/12 로 설정되어 있는 것을 볼 수 있다. 이는 10.96.0.0 ~ 10.111.255.255의 범위를 갖는 것을 알 수 있다.
- 여기서 언급할 상대적인 중요한 점은 파드 네트워킹을 설정할 때 파드 네트워크 CIDR 범위로 10.244.0.0/16을 제공했다.
- 이렇게 각 네트워크에 대해 지정하는 범위가 겹치지 않아야 한다. 각각에는 자체적인 IP 범위가 있어야 한다. 파드와 서비스가 동일한 IP 주소를 할당받는 일이 없어야 한다. 그래서 서비스가 10.103.132.104라는 IP 주소를 얻게된다.
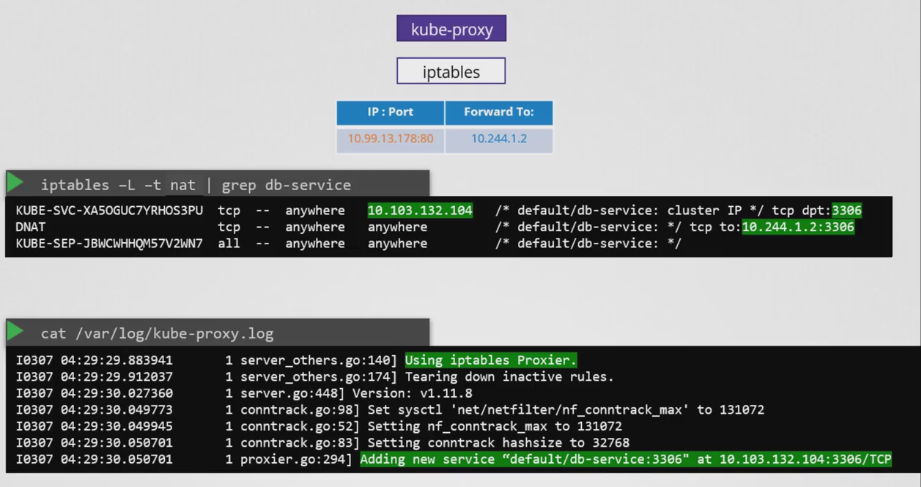
- kube-proxy에서 생성한 규칙은 iptables NAT 테이블 출력에서 확인할 수 있다.
- kube-proxy에 의해 생성된 모든 규칙에는 해당 서비스 이름이 주석으로 달려 있으므로 서비스의 이름을 grep으로 검색하면 된다.
- 위 이미지와 같이 서비스의 IP 주소인 10.103.132.104의 포트 3306으로 이동하는 모든 트래픽은 대상 주소를 10.244.1.2로 변경해야 한다는 것을 의미하며, 이는 파드의 IP 주소의 포트 3306이다. 이 작업은 DNAT 규칙을 추가함으로써 수행된다.
- 마찬가지로 NodePort 유형의 서비스를 생성할 때, kube-proxy는 모든 노드에서 특정 백엔드 파드로 오는 모든 트래픽을 전달하기 위해 iptables 규칙을 생성한다.
- kube-proxy 로그 자체에도 이런한 항목들이 생성되는 것을 확인할 수 있다. 로그에서는 어떤 Proxier를 사용하는 지 찾을 수 있다. 이 경우 iptables이며, 그런 다음 db-service를 추가할 때 항목을 추가한다.
- log 파일의 위치는 설치에 따라 다르므로 프로세스의 verbosity level을 확인해야 한다.
DNS in kubernetes
- 이 강의에서는 어떤 이름이 어떤 객체에 할당되는지, 서비스 DNS 레코드, 파드 DNS 레코드에 대해 알아보고 한 파드에서 다른 파드로 어떻게 도달할 수 있는지 살펴볼 것이다.
- 우리는 세 노드 쿠버네티스 클러스터를 가지고 있으며 그 위에 일부 파드와 서비스가 배포되어 있다.
- 각 노드에는 노드 이름과 할당된 IP 주소가 있다. 클러스터의 노드 이름과 IP 주소는 당신의 조직의 DNS 서버에 등록되어 있을 것이다.
- 이 강의에서는 클러스터 내의 다양한 구성 요소 간, 예를 들어 파드와 서비스 사이에서 DNS 해결에 대해 논의한다.
- 쿠버네티스는 클러스터를 설정할 때 기본적으로 내장 DNS 서버를 배포한다. 수동으로 쿠버네티스를 설정한다면 직접 배포해야한다.

- 우선 두개의 파드와 서비스를 가지고 시작해보자.
- 왼쪽에는 IP가 10.244.1.5로 설정된 테스트 파드가 있고, 오른쪽에는 IP가 10.244.2.5로 설정된 웹 파드가 있다.
- 그들의 IP를 보면 두 개의 다른 노드에 호스팅 되었을 것으로 추측되지만, DNS 측면에서는 그렇게 중요하지 않다. DNS가 고려될 때 모든 파드와 서비스는 IP 주소를 사용해 서로에게 도달할 수 있다고 가정한다.
- 웹 서버를 테스트 파드에서 접근 가능하게 만들기 위해 서비스를 만든다. 이를 web-service라고 하고, 서비스는 10.107.37.188 IP를 받는다.
- 서비스가 생성될 때마다 쿠버네티스 DNS 서비스는 서비스에 대한 레코드를 생성한다. 이는 서비스 이름을 IP 주소에 매핑하며, 따라서 클러스터 내에서 어떤 파드에서든 서비스 이름을 사용해 이 서비스에 도달할 수 있다.
- 네임스페이스는 동일한 이름 공간에 있는 모든 사람은 서로에게 이름만 사용해 주소를 지정하고 다른 이름 공간에 있는 누군가에게는 전체 이름을 사용한다.
- 이 경우 테스트 파드와 웹 파드, 그리고 관련된 서비스가 모두 동일한 네임스페이스인 default 네임스페이스에 있으므로 테스트 파드에서 웹 서비스에 단순히 서비스 이름 web-service 를 사용해 도달할 수 있다.
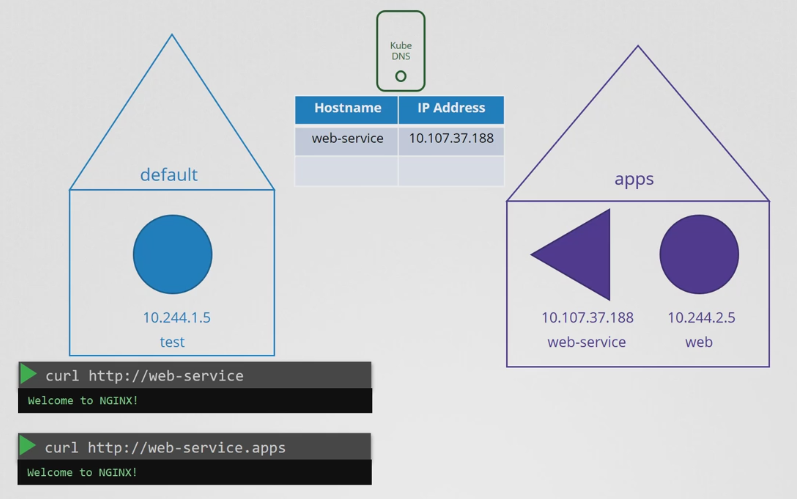
- 만약 웹 서비스가 apps라는 별도의 네임스페이스에 있다면 어떤가?
- 그럼 default 네임 스페이스에서는 이를 참조하기 위해 web-service.apps라고 해야한다. 여기서 web-service는 서비스의 이름이고, apps는 네임스페이스의 이름이다.
- 각 네임스페이스마다 DNS 서버는 그 이름과 동일한 서브 도메인을 만든다. 네임 스페이스에 대한 모든 파드 및 서비스는 네임스페이스의 이름을 가진 서브 도메인 내에 그룹화된다.
- 모든 서비스는 또 다른 서브 도메인인 svc라는 다른 서브 도메인에 그룹화 된다. 결과적으로 web-service.apps.svc라는 이름으로 도달할 수 있다.

- 그리고 모든 서비스와 파드는 클러스터에 대한 루트 도메인에 그룹화되어 있으며, 기본적으로 cluster.local로 설정되어 있다. 따라서 서비스에는 web-service.apps.svc.cluster.local 이라는 url을 사용해 액세스할 수 있다.
- 이것이 서비스의 완전한 FQDN 정규 도메인 이름이다.
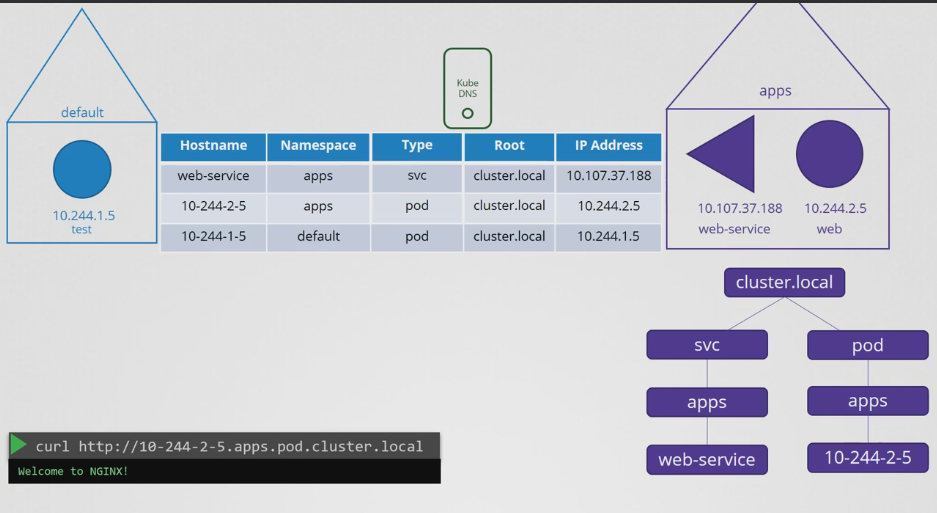
- 파드는 어떠한가? 파드에 대한 레코드는 기본적으로 생성되지 않지만 명시적으로 활성화 할 수 ㅇㅅ다. 파드는 파드 이름을 사용하지는 않고 IP 주소의 점을 대시로 대체하여 이름을 생성한다.
- 네임스페이스는 동일하게 유지되고 유형은 파드로 설정되며 루트 도메인은 항상 cluster.local이다.
- 10-244-2-5.apps.pod.cluster.local
CoreDNS in Kubernetes
- 이 강의에서는 쿠버네티스가 클러스터 내에서 DNS를 어떻게 구현하는 지에 대해 논의할 것이다.
- 두 개의 IP 주소를 가진 두 개의 파드가 주어졌을 때 DNS 통신을 하고자 한다면 각각의 /etc/hosts 파일에 항목을 추가하는 것이 간단한 방법이다.
- 수천 개의 파드가 클러스터에 있고 수백 개가 매분 생성 및 삭제되는 경우 적절한 해결책은 아니다.
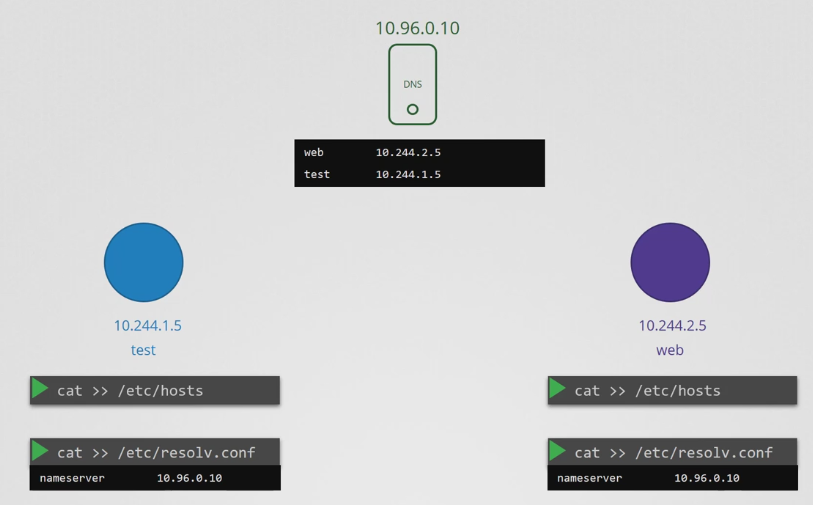
- 따라서 이런 작업을 해주는 것을 중앙 DNS 서버로 맡기고 파드를 DNS 서버로 지정하기 위해 각각의 /etc/resolv.conf 파일에 항목을 추가해 네임서버를 DNS 서버의 IP 주소인 10.96.0.10로 설정해준다.
- 새로운 파드가 생성될 때마다 DNS 서버에 해당 파드에 대한 레코드를 추가해 다른 파드가 새로운 파드에 액세스할 수 있도록하고, 파드의 /etc/resolv.conf 파일을 구성해 DNS 서버를 가리키도록 해 새로운 파드가 클러스터 내의 다른 파드를 resolv할 수 있도록 한다.
- 이것이 쿠버네티스가 하는 방식과 유사하지만, 이전 강의에서 본 것처럼 파드 이름을 해당 IP 주소와 매핑하는 항목은 생성하지 않았다.
- 쿠버네티스는 클러스터 내에서 DNS 서버를 배포한다.
- 버전 1.12 이전에 쿠버네티스에서 구현된 DNS 서버는 kube-dns로 알려져있다. 쿠버네티스 버전 1.12 이후로는 coreDNS로 변경되었다.
- 클러스터에서 coreDNS는 어떻게 설정되어 있을까?
- coreDNS 서버는 쿠버네티스 클러스터의 kube-system 네임스페이스에 파드로서 배치된다. 여분의 안정성을 위해 레플리카셋의 일부로 두 개의 파드로 배치된다. 실제로 이는 deployment 내의 레플리카셋이다.
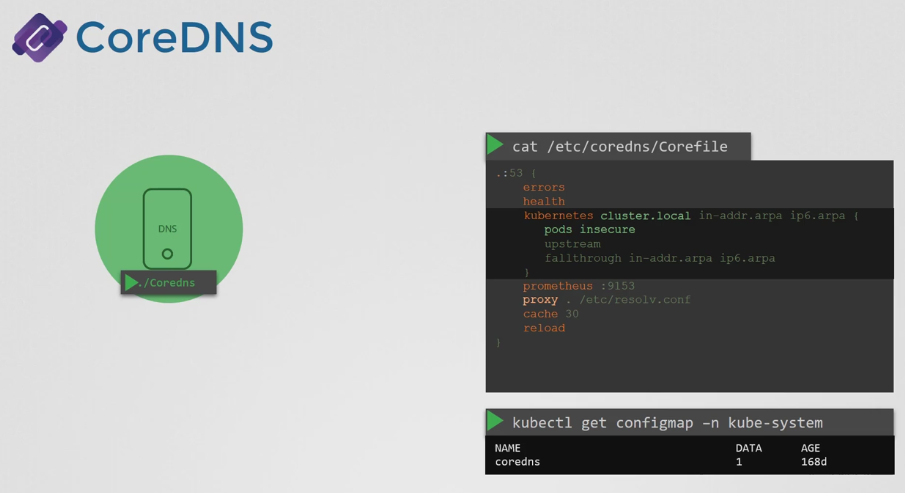
- CoreDNS는 파드로 배포된다고 알고있다. 이 파드는 CoreDNS 실행 파일을 실행하며, 우리가 CoreDNS를 배포할 때 실행한 실행 파일과 동일하다.
- CoreDNS에는 config 파일이 필요하다. /etc/coredns/Corefile 이라는 파일을 사용한다.
- 이 파일에서는 여러 플러그인이 구성된다. 플러그인은 오류 처리, health check, 모니터링 메트릭, 캐시 등을 처리하기 위해 구성된다.
- CoreDNS를 쿠버네티스와 함께 작동하도록 만드는 플러그인은 쿠버네티스 플러그인이며, 여기서 클러스터의 최상위 도메인 이름이 설정된다. 위 이미지의 경우 cluster.local이다. 따라서 CoreDNS 서버의 모든 레코드는 이 도메인 하에 속한다.
- 쿠버네티스 플러그인을 사용하면 여러 옴션이 있다.
- 옵션 중 하나인 "pods"는 클러스터의 각 파드에 대한 레코드를 생성하는 역할을 한다. 기본적으로 비활성화되어 있지만, 이 항목을 통해 활성화할 수 있다.
- DNS 서버가 해결할 수 있는 모든 레코드는 예를들어 파드가 www.google.com으로 액세스하려 할 때 CoreDNS 파드의 /etc/resolv.conf에 지정된 nameserver로 전달된다.
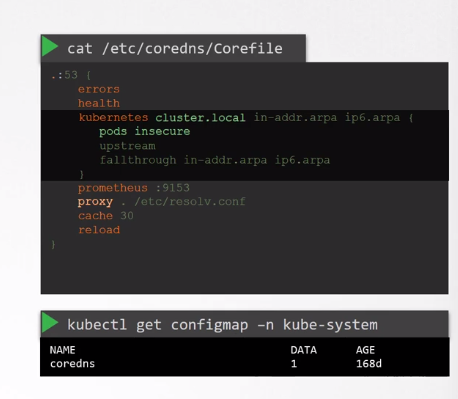
- 또한 이 corefile은 configmap으로 pod에 전달된다. 이렇게 하면 이 corefile에서 수정을 해야 할 경우 configmap 객체를 편집할 수 있다.

- 적절한 쿠버네티스 클러그인을 사용해 CoreDNS 포드가 실행 중이다. 이는 쿠버네티스 클러스터에서 새로운 파드나 서비스를 감시하며, 파드나 서비스가 생성될 때마다 데이터베이스에 해당 레코드를 추가한다.
- 그 다음으로 파드가 CoreDNS 서버를 가리키도록 한다. 파드가 DNS 서버에 도달하기 위해 어떤 주소를 사용할까?
- CoreDNS 솔루션을 배포할 때 클러스터 내의 다른 구성 요소에서 사용할 수 있도록 서비스를 생성한다.
- 기본적으로 이 서비스의 이름은 kube-dns이다. 이 서비스의 IP 주소가 파드에서 nameserver로 구성된다.
- 파드의 DNS 구성은 파드가 생성될 때 쿠버네티스가 자동으로 수행한다. 이를 수행하는 쿠버네티스 구성요소는 kubelet이다.
- kubelet의 구성 파일인 /var/lib/kubelet/config.yaml을 확인해보면 DNS 서버와 도메인의 IP가 표시된다.
- 한번 파드가 올바은 nameserver로 구성되면, 이제 다른 파드와 서비스를 해결할 수 있다. 웹 서비스에는 단순히 web-service또는 FQDN을 이용한 네임으로 액세스할 수 있다.
- dnslookup 또는 host 명령을 사용해 웹서비스를 수동으로 조회하면 web-service.default.svc.cluster.local 이라는 완전한 FQDN 이름이 반환된다. 우리는 단순히 web-service라고만 해도 접속이 된다. 어떻게 전체 이름을 조회 했는가?

- 실은 resolv.conf 파일에 검색 항목이 있다. 이는 default.svc.cluster.local 뿐만 아니라 svc.cluster.local 또는 cluster.local로 설정되어 있다.
- 이를 통해 web-service나 web-service.default 와 같은 어떤 이름으로든 서비스를 찾을 수 있다.
- 그러나 Service에 대한 검색 항목만 있으므로 파드에 동일한 방식으로 액세스할 수 없다. 이를 위해서는 파드의 전체 FQDN을 지정해야 한다.
반응형
'자격증 > Kubernetes CKA' 카테고리의 다른 글
| [CKA] Install "Kubernetes the kubeadm way" (0) | 2023.12.31 |
|---|---|
| [CKA] Networking - 3 (0) | 2023.12.30 |
| [CKA] Networking - 1 (1) | 2023.12.26 |
| [CKA] Storage (0) | 2023.12.19 |
| [CKA] Security - 3 (0) | 2023.12.18 |