
반응형

Scheduling
강의 개요
- 스케줄러의 행동 방식을 사용자 지정하고 구성하는 다양한 옵션
- 수동 스케줄링 방법 및 데몬셋, 레이블, 셀렉터, Requirements와 Limit
- 다중 스케줄러를 구성하는 방법과 스케줄러 이벤트 보는 법
수동 스케줄링
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01- 클러스터에 스케줄러가 없으면 내장된 스케줄러에 의존하는 대신 파드를 직접 스케줄링 해야 한다.
- nodeName 이라는 필드는 파드 매니페스트 파일을 만들 때 지정하진 않고 쿠버네티스가 자동으로 추가한다.
- 스케줄러는 모든 파드를 확인해 nodeName 속성이 설정되지 않은 것을 찾는다.
- 이러한 파드들은 스케줄링하기 위한 후보가 된다. 그 다음 스케줄링 알고리즘을 실행하여 파드에 맞는 노드를 식별한다.
- 식별되면 바인딩 object를 생성해 nodeName 속성을 노드 이름으로 설정해 노드안에 파드를 예약한다.
- 만약 노드를 모니터링하고 예약할 스케줄러가 없으면 어떻게 되나요?
- 파드는 계속 pending 상태에 머물러 있을 것이다.
- 이렇게 되지 않기 위해서는 직접 노드에 파드를 수동으로 할당하는 것이다.
- nodeName 필드를 파드 specification file에 있는 nodeName으로 설정하고 파드를 생성하는 것이다.
- nodeName을 기준으로 지정된 노드에 파드가 할당된다. 그럼 관리자는 파드를 생성할 때만 노드를 설정할 수 있다.
- 만약 파드가 이미 생성되었고 파드를 노드에 할당하길 원하면 어떻게 해야하는가?
- 쿠버네티스는 파드 nodeName을 수정하는 것을 허용하지 않으므로 기존 파드에 노드를 할당하는 다른 방법은 binding object를 생성해 pod의 바인딩 API에 POST 요청을 보내는 것이다. 이는 실제 스케줄러가 수행하는 것을 모방하는 것이다.
- 바인딩 개체에서 노드의 이름으로 대상 노드를 지정한 다음 데이터가 JSON 형식으로 바인딩 개체에 설정된 파드의 바인딩 API에 POST 요청을 보낸다.
- 따라서 YAML 파일을 JSON 형태로 변환해야 한다.
Label과 Selectors
- 레이블과 셀렉터는 그룹으로 묶는 표준 방법이다.
- 예를 들어 다양한 인종의 사용자를 등급이나 종류에 따라 분류하고자 할 때 특정 기준으로 필터링해야한다. 예를들어 흑인종, 백인종, 도시에 사는 사람, 시골에 사는 사람 등등
- 그 분류가 무엇이든 간에 필요에 따라 분류하고 여과할 능력이 필요한데, 가장 좋은 방법이 레이블을 이용하는 것이다.
- 레이블은 각 물품에 부착된 속성이다. 등급, 종류, 색깔에 따라 각각의 물품에 속성을 추가하는 것이다.
- 셀렉터는 이 항목들을 필터링하는 것을 도와준다.
- 예를 들어 포유류, 녹색 이라고 하면 녹색 포유류가 나온다.
- 쿠버네티스는 파드, 서비스, 레플리카셋, 디플로이먼트 등에서 다양한 유형이 생성되는 데 각기 다른 카테고리로 필터링하고 볼수 있는 방법으로 레이블과 셀렉터를 이용한다.
- 특정 개체를 필터링하기 위해서는 app=app1 과 같이 key=value 형태로 레이블을 지정한다.
- 파드 매니페스트 파일에서 metadata.labels 필드를 이용해 label을 이용한다.
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80- 위와 같은 파일에서는 metadata 아래에 environment=production, app=nginx 두 개의 레이블이 있는 것이다.
- 파드 뿐만 아니라 쿠버네티스 오브젝트는 내부에서 레이블과 셀렉터를 이용해 서로 다른 오브젝트를 연결한다
- 레플리카셋의 경우 파드와는 또 다르다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
function: webserver
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3- 레플리카셋은 먼저 파드에 대한 정의를 레이블링하고 레플리카셋의 셀렉터를 이용해서 파드를 그룹으로 묶는다.
- 레플리카셋 매니페스트에서는 두 곳에서 정의된 레이블을 확인 할 수 있다.
- template 아래 정의된 레이블은 파드의 레이블이다.
- 맨 위의 metadata 아래 정의된 레이블은 레플리카셋 자체의 레이블이다.
- 레플리카셋 자체의 레이블은 레플리카셋을 발견하기 위해 다른 개체를 구성할 때 사용된다.
- 레플리카셋을 파드에 연결하기 위해 레플리카셋 사양에 따라 셀렉터 필드를 구성하고 파드에서 정의된 레이블과 일치하게 만들면 파드를 그룹으로 묶을 수 있다.
- 하지만, 같은 레이블을 가진 다른 파드가 기능이 다르다면 새로 레이블을 구성해 두 개의 레이블을 지정해줄 수 있다.
- 레플리카셋이 생성될 때 레이블이 일치하면 레플리카셋은 성공적으로 생성된다.
- 서비스와 같은 다른 개체에 대해서도 동일하게 작동된다.
- 서비스 definition file에 정의된 셀렉터를 사용해 레플리카셋 매니페스트 파일에 있는 파드의 레이블을 확인한다.
Annotations
- 어노테이션 (=주석) 은 정보 수집 목적으로 다른 세부 사항을 기록하는 데 사용된다.
- 레이블과 같이 필터링을 하거나 분류하기 위해서 사용하는 것은 아니다.
- 예를 들어 이름, 버전, 빌드 정보 같은 세부 정보나 연락처, 전화번호, 이메일 ID 등은 통합 목적으로 사용 가능하다.
Taints 와 Tolerations
- 비유적으로 표현하자면 테인트는 사람 몸에 벌레가 앉는 걸 막기 위한 방충 스프레이라고 볼 수 있다.
- 벌레는 냄새를 잘 못 참아서 사람에게 다가갈 때 테인트를 발라 놓으면 벌레가 떨어진다.
- 그런데 냄새를 잘 견디는 다른 벌레가 있을 수도 있다. 그래서 방충 스프레이의 영향을 받지않고 사람 몸에 앉는 벌레가 있을 수도 있다.
- 벌레가 사람 몸에 앉는걸 결정하는 건 두 가지이다.
- 첫째는 사람이 테인트라는 방충 스프레이를 바르는 것
- 둘째는 벌레가 테인트라는 방충 스프레이를 참을 수 있는 정도
- 돌아와서 사람은 노드고 벌레는 파드이다.
- 테인트나 톨러레이션은 보안이나 침입과는 상관이 없고, 한 노드에 어떤 파드로 스케줄링할 수 있는 지 제한을 설정하기 위해서 사용된다.
- 파드가 생성되면 쿠버네티스 스케줄러는 이 파드를 가능한 워커 노드에 두려고 한다.
- 초기 상태에는 제한이 없이 스케줄러가 모든 노드에 파드를 배치해 균형이 맞도록 한다.
- 특정 사용 사례나 응용 프로그램에 대해 노드 1에 전용 리소스가 있어서 이 응용 프로그램에 속한 파드만 노드 1에 배치하고 싶으면 어떻게 해야하나?
- 노드에 테인트를 설정해서 구체적으로 명시하지 않는 한 어떤 파드도 노드에 허용될 수 없게 한다.
- 특정 파드에게 테인트의 내성을 갖게 하기 -> 톨러레이션
- 이렇게 하면 스케줄러가 노드 1에 파드를 배치하고 싶어도 테인트와 톨러레이션이 적절히 설정되지 않으면 계속 노드 2 또는 노드 3에게 파드를 배치할 것이다.
- 명령어는 아래와 같다.
kubectl taint nodes node1 key1=value1:<taint effect>- 테인트는 세 가지 효과를 가지고 있다.
- NoSchedule : 앞서 설정한 조건에 맞는 테인트가 하나 이상 있으면 해당 노드에 파드를 더 이상 스케줄하지 않는다.
- PreferNoSchedule : 앞서 설정한 조건에 맞는 테인트가 하나 이상 있으면 더 이상 가급적 배포하지 않지만 무조건 적으로 배포하지 않는 것은 아니다. 다른 노드에 자원이 모자르거나 하면 배포됨
- NoExecute : 앞서 설정한 조건에 맞는 테인트가 있는 파드는 무조건 스케줄링하지 않는다. 노드에서 이미 실행 중인 파드도 포함되어 파드를 축출하고 아직 실행되지 않은 경우에도 스케줄링 되지 않는다.
- 주의해야 할 점은 NoSchedule과 NoExecute의 차이인 것 같다. NoExecute는 기존에 있는 파드도 다른 노드로 옮겨버린다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
# operator가 Equal인 경우 아래와 같을 듯
tolerations:
- key: "example-key"
operator: "Equal"
value: "example"
effect: "NoSchedule"- 또한 operator에 따라서 달라 배포 가능성이 달라진다.
- Equal 인 경우 key 와 value, effect 값을 동시에 비교한다.
- Exists 인 경우 key와 effect 값 만을 비교한다. value 값이 없어야 한다.
- 지정하지 않은 경우 operator 는 Equal이 기본 값이다.
- 스케줄러는 마스터 노드의 어떤 파드도 스케줄링하지 않는다. 쿠버네티스 클러스터가 처음 설정되면 마스터 노드에 테인트 설정이 자동으로 돼 이 노드에 파드가 지정되는 걸 막는다.
- 필요한 경우 이 동작을 수정할 수도 있는데, 모범 사례는 마스터 노드에 Application을 배포하지 않는 것이다.
Node Selectors
- 기본적으로 파드는 어떤 노드던지 배포될 수 있다.
- 그런데 SSD가 장착된 노드에 파드가 배포되도록 하거나 많은 통신을 하는 두 개의 서로 다른 애플리케이션의 파드를 동일한 가용 영역에 배치하는 경우가 있다.
- 이런 경우 파드가 어떤 노드에 배포 되어야할 지 제어해야 하는 경우도 있다.
- 두 가지 방법이 있다.
- 첫번째는 nodeSelector 노드 셀렉터이다.
- 간단하고 쉬운 방법이다. 파드의 매니페스트 파일에 spec 밑에 있는 nodeSelector 필드를 추가해 레이블을 매핑하는 방법이다.
- 타겟으로 삼고자하는 노드가 가지고 있는 노드 레이블을 명시해주면 된다.
apiVersion: v1
kind: Pod
metadata:
name: httpd
labels:
env: prod
spec:
containers:
- name: httpd
image: httpd
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd- 두 번째는 nodeAffinity 노드 어피니티이다.
Node Affinity
- nodeAffinity는 파드가 특정 노드에 호스트될 수 있도록 하는 것이다.
- affinity 와 anti-affinity를 이용해서 nodeSelector보다 더 많은 선택 로직을 제공한다.
- 노드 어피니티는 두 종류가 있다.
- requiredDuringSchedulingIgnoredDuringExecution : 이 규칙이 만족되지 않으면 스케줄러가 파드를 스케줄링할 수 없다.
- preferredDuringSchedulingIgnoredDuringExecution : 스케줄러는 조건을 만족하는 노드를 찾으려고 노력한다. 해당되는 노드가 없더라도, 스케줄러는 여전히 파드를 스케줄링한다. 예를 들어 해당 조건에 부합하지 않는 노드
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0- operator는 규칙을 해석할 때 사용할 논리 연산자를 지정할 수 있다. 아래와 같다.
- In : 레이블이 지정되어 있는 노드에 해당 파드를 배치해라.
- NotIn : 레이블이 지정되어 있지 않은 노드에만 해당 파드를 배치해라
- Exitsts : value는 신경쓰지 않고 단순히 레이블만 있다면 해당 파드를 배치해라
- DoesNotExist : value는 신경쓰지 않고 레이블이 없다면 파드를 배치해라
- Gt : Greater than의 약자. 이 값이 레이블의 값보다 큰 경우 파드를 배치해라. 값은 무조건 정수형이어야 함
- Lt : Less Than의 약자. 이 값이 레이블의 값보다 작은 경우 파드를 배치해라. 값은 무조건 정수형이어야 함
- 필수 유형 즉 required 유형을 선택하면 스케줄러는 지정된 Affinity 규칙과 함께 파드를 노드에 놓도록 지시한다.
- 파드를 못찾으면 스케줄링도 하지 못한다. required 유형은 파드의 배치가 중요한 경우에 사용된다. 일치하는 노드가 존재하지 않으면 파드는 스케줄링되지 않는다.
- 그러나 파드 배치가 스케줄링을 실행하는 것보다 덜 중요하다고 가정을 해보자
- 이 경우엔 preferred 규칙으로 설정하고 일치하는 노드를 찾을 수 없는 경우 스케줄러는 node affinity를 무시하고 사용 가능한 노드에 파드를 배치한다.
- 특정 노드를 하나 찾는 게 아니라 아무데나 배치하는 것을 의미한다.
- preferredDuringSchedulingIgnoredDuringExecution 을 잘 보면 DuringScheduling DuringExecution 두 가지 상태가 있는 것을 알 수 있다.
- DuringScheduling 상태는 파드가 존재하지 않고 처음 생성된 상태이며, 처음 생성될 때 지정된 어피니티 규칙에 따라 파드를 올바른 노드에 배치하는 것
- DuringExecution 상태는 파드가 실행 중이고 노드의 레이블 변경과 같이 node affinity에 영향을 미치는 환경이 변경된 상태이다.


- IgnoredDuringExecution 과 반대로 RequiredDuringExecution type도 있다. 실행 중인 파드에 대한 상태도 있다. Affinity를 설정 시 규칙을 충족하지 않는 노드에서 실행 중인 모든 파드를 evict(퇴거,퇴출) 시키는 옵션이다.
Taints and Tolerations vs Node Affinity
- 예시를 들어 설명을 해본다.
- 노드 세 개와 파드 세 개가 각각 세 가지 색이다. 파랑 빨강 초록
- 궁극적인 목표는 파란 파드를 파란 노드에 놓고 빨간 파드를 빨간 노드 초록도 마찬가지다.
- 다른 팀들과 같은 클러스터를 사용 중이기 때문에 위에서 이야기한 색깔 파드 외에도 신경을 써야한다.
- 빨강, 파랑, 초록 각 노드에 테인트를 설정하고 각각의 노드에 파드가 들어갈 수 있도록 톨러레이션도 설정한다.
- 파드가 생성되면 노드는 올바른 수용력을 가진 파드만 받아들인다.
- 허나 테인트와 톨러레이션만 설정한다고 파드가 설정된 노드에만 프로비저닝 된다는 보장은 없다.
- 결국 빨간 파드는 테인트와 롤러레이션이 설정되지 않은 다른 노드들 중 하나에게 가게된다.
- 이것은 우리가 생각하는 요구사항이 아니다.
- Affinity를 사용해 노드에 각각의 색으로 레이블을 설정한다.
- 그리고 나서 파드들을 노드에 묶기 위해 노드 셀렉터를 설정한다.
- 특정한 파드를 특정 노드에 프로비저닝하기 위해 테인트 톨러레이션 그리고 노드 어피니티를 함께 사용할 수 있다.
- 먼저 다른 파드들이 우리의 노드에 배치되는 것을 방지하기 위해 테인트와 톨러레이션을 설정하고, 그리고 나서 우리의 파드들이 그들의 노드에 배치되는 것을 방지하기 위해 Affinity을 사용한다.
Resource Request and Limits
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"- Request를 먼저 보자
- 3개의 노드를 가진 클러스터가 있다.
- 각 노드엔 사용 가능한 CPU와 메모리 Resource가 있다.
- 모든 파드를 운영하려면 Resource가 필요하다. 노드의 Resource를 사용하는 개념으로 보면 된다.
- 파드는 CPU 2개와 메모리 유닛 1개가 필요하다고 가정해보자.
- 파드가 노드에 놓일 때마다 노드에 있는 사용 가능한 리소스를 소비한다.
- 쿠버네티스 스케줄러는 파드가 갈 노드를 결정한다. 그 과정에서 Request resource를 고려한다. 그리고 파드를 설치할 최적의 노드를 식별한다.
- 이 경우 스케줄러는 2번 노드에 새 파드를 스케줄링한다.
- 해당 노드에 사용 가능한 리소스가 없으면 스케줄러는 해당 노드에 파드를 두는 것을 피하고 충분한 리소스가 사용 가능한 곳에 파드를 놓는다.
- 위 yaml 파일 예제를 보면 requests 항목이 있다. 파드를 만들 때 필요한 CPU와 메모리의 양을 지정할 수 있다.
- 스케줄러는 파드를 노드에 배치할 때 이 숫자를 이용해 사용 가능한 충분한 양의 리소스가 있는 노드를 식별한다.
- CPU의 경우 "100m" 또는 0.1로 표현할 수 있다. CPU 1 은 vCPU를 의미한다.
- 메모리도 동일하게 "256Mi" 와 같이 표현할 수 있다.
- Limit을 보자
- 파드의 한도를 지정할 수도 있다.
- 예를 들어 컨테이너에 vCPU 1로 제한하면 컨테이너는 그 노드에서 vCPU 1만 사용하도록 제한할 것이다. 메모리도 마찬가지다.
- 파드 매니페스트의 리소스 섹션에서 limit을 지정할 수 있다.
- 파드가 만들어지자 쿠버네티스는 컨테이너에 새로운 한계를 정할 수 있다. 파드 내 컨테이너마다 제한과 요청을 설정할 수 있다는 것을 기억해야한다.
- CPU의 경우 시스템이 CPU를 조절해 절대 Limit을 넘지 않도록 한다.
- 메모리의 경우는 다르다. 메모리는 컨테이너 Limit 보다 많은 메모리를 사용할 수 있다. 하지만, 메모리를 Limit보다 많이 사용하면 어떻게 되는가? OOM Kill 에러로 인해 파드가 종료될 것이다.
- 기본적으로는 Request 나 Limit가 설정되어 있지 않다. 그 말은 어떤 파드든 어떤 노드에서 요구되는 만큼의 자원을 소비하고 리소스 노드에서 실행 중인 다른 파드나 프로세스에 영향을 미칠수 있다는 말이다.
- 또한 Limit이 설정되어 있지 않으면 파드 하나가 노드의 모든 리소스를 소비하고 두 번째 리소스 요구를 막을수도 있다.
- 만약 Request는 설정되어 있지 않고 Limit만 설정된 경우 자동으로 Request를 Limit과 동일하게 설정한다.
- 만약 Request만 설정된 경우 Limit이 설정되어 있지 않기 때문에 파드마다 CPU 및 자원을 최대한 많이 사용할 수 있다.
- Limit을 설정하는 경우는 사용자가 인프라를 오용하는 것을 막기 위해 제한한다. 예를 들어 비트코인 채굴이나 다른 리소스 소비 활동을 싱행하는 것을 막기 위해서
- 하지만 Limit 을 설정하지 않을 수도 있다. 허나 Limit 을 설정하지 않으려면 모든 파드에 Request 설정이 되어 있어야한다. 그래야만 다른 파드에 대한 Limit이 없을 때 파드가 자원을 보장받을 수 있다.
- Request 나 Limit이 없는 파드가 있다면 노드에서 사용 가능한 CPU나 메모리를 모두 소모하고 정의되지 않은 파드는 제한할 수 있다.
- 모든 노드에 대한 Request를 설정하는 것이 좋다.
- Limit이 설정되어 있지 않은 파드가 다른 파드를 죽이는 것을 방지하기 위해서는 limitRange를 이용해야 한다.
LimitLange
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # 이 섹션에서는 기본 한도를 정의한다
cpu: 500m
defaultRequest: # 이 섹션에서는 기본 요청을 정의한다
cpu: 500m
max: # max와 min은 제한 범위를 정의한다
cpu: "1"
min:
cpu: 100m- LimitRange는 파드의 기본 값을 정의하는 데 도움을 준다. 파드 매니페스트 내 Request나 Limit 없이 생성된 컨테이너에 대한 기본 값을 정의하는 데 도움을 준다.
- 네임 스페이스 별로도 설정이 가능하다. LimitLange는 오브젝트이다.
- 설정 항목은 아래와같다.
- default : 기본 Limit을 정의
- defaultRequest : 기본 request 값을 정의
- max : 제한 최대 리소스
- min : 제한 최소 리소스
ResourceQuotas
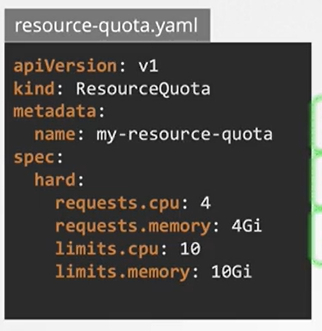
- 위와 같이 설정 가능하다.
- 리소스 쿼터는 모든 파드가 이만큼의 CPU나 메모리를 소비해선 안된다고 할 수 있다. 네임스페이스 레벨 객체로 요청과 한계에 대한 엄격한 제한을 설정하기 위해 사용한다.
- 위 리소스 쿼터는 현재 네임스페이스에서 요청된 총 CPU를 4로 제한한다. 메모리는 4 Gib 로 제한한다.
- 현재 네임스페이스에서 총 CPU 합을 10으로 제한한다. 메모리의 총합을 10 GiB로 제한한다.
Daemonset
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
# it may be desirable to set a high priority class to ensure that a DaemonSet Pod
# preempts running Pods
# priorityClassName: important
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log- 데몬셋은 복제 집합 같은 것이다. 여러 개의 인스턴스 파드를 배포하도록 도와준다.
- 하지만 레플리카셋과 같은 것과 다르게 클러스터의 노드마다 파드를 하나씩 실행한다.
- 클러스터에 새 노드가 추가될 때마다 파드 복제본이 자동으로 해당 노드에 추가된다. 노드가 제거되면 파드는 자동으로 제거된다.
- 데몬셋은 모니터링 에이전트나 로그 컬렉터를 클러스터 내 각 노드에 배포하는 경우 사용하기도 한다.
- 앞서 쿠버네티스에서는 클러스터 내 모든 노드에 필요한 워커 노드 구성 요소 중 하나가 kube-proxy란 걸 알고있다. 데몬셋의 좋은 예이다.
- 다른 사용 사례는 네트워킹인데, weave-net 과 같은 네트워킹 솔루션이다.
- 데몬셋을 만드는건 레플리카셋을 만드는 것과 유사하다.
- 템플릿 섹션과 셀렉터에 파드 사양을 포함해 데몬셋과 파드를 연결한다.
- 어떻게 각 노드의 파드를 스케줄링하고 어떻게 모든 노드에 파드가 있는지 확실히 하는가?
- 각 파드에서는 스펙에서 nodeName 속성을 생성되기 전에 설정한다.
- 생성되면 각각의 노드에 자동으로 생성되게 된다.
- 쿠버네티스 1.12v 까지는 위와 같은 과정이었다.
- 쿠버네티스 1.12v 이후 부터는 스케줄러와 nodeAffinity를 이용해서 데몬셋 파드를 특정 노드에 위치 시킨다.
Static Pods
- 정적 파드는 API 서버 없이 특정 노드에 있는 kubelet 데몬에 의해 직접 관리된다.
- 컨트롤 플레인에 의해 관리되는 파드와는 달리, kubelet이 각각의 스태틱 파드를 감시(실패 시 재구동)한다.
- 스태틱 파드는 항상 특정 노드에 있는 kubelet에 묶여 있다.
- Kubelet은 그럼 kube api 서버 없이 어떻게 파드의 manifest 파일을 kubelet에 제공할수 있는지?
- kubelet을 설정하면 파드가 정의된 파일을 읽을 수 있다. 파드에 관한 정보를 저장하는 서버의 디렉터리에서
- 이 디렉터리에 파드 정의 파일을 두면 kubelet이 주기적으로 이 디렉터리를 확인하고 파일을 읽고 호스트에 파드를 만들고 파드의 생존을 보장한다.
- 파일을 수정하면 파드를 재생성한다.
- 파일을 삭제하면 파드를 삭제한다.
- Kubelet은 파드 수준으로 일해서 파드만 이해할수 있다. 따라서 레플리케이션 컨트롤러에서 생성하는 자원에 대한 관리는 불가하다. 예를들어 레플리카셋, 데몬셋, 디플로이먼트 등등
- /etc/Kubernetes/manifests
- 스태틱으로 생성된 경우 docker ps 와 같은 명령어를 사용해야한다. kubectl 명령어는 kube api 서버와 통신하기 때문에
- 또한 각각의 스태틱 파드에 대해 쿠버네티스 API 서버에서 미러 파드를 생성하려고 자동으로 시도한다. 즉, 워커 노드에서 구동되는 파드는 api 서버에 의해서 볼 수 있지만 api 서버에서 제어될 수는 없다.
- 만약 워커 노드에서 생성한 static 파드를 제거하기 위해서는 해당 파드가 생성된 워커 노드로 직접 들어가 삭제해야한다.
- 일단 노드로 접속해야한다. ssh INTERNAL-IP 로 워커 노드에 접속 해준다.
- /var/lib/kubelet/ 에 이동해주면 config.yaml 파일이 있다.
- 해당 파일을 확인해보면 staticPodPath: 필드가 있을 것이다. 여기가 쿠블렛의 static pod 가 위치한 곳이다.
- 들어가서 yaml 파일을 확인해주면 된다.
Multiple Schedulers
- 테인트, 톨러레이션, 노드 어피니티를 통해 우리가 지정하는 다양한 조건으로 파드를 생성할 수 있다.
- 그러나 이 중에 만족스러운게 없다면? 고유의 사용자 지정 조건을 추가하고 체크인할 수 있다.
- 쿠버네티스는 스케줄러 프로그램을 작성해 기본 스케줄러로 패키지하거나 쿠버네티스 클러스터에서 추가 스케줄러로 배포할 수 있다.
- 그리고 일부 특정 애플리케이션 즉 파드를 고유의 사용자 지정 스케줄러를 사용할 수 있다.
- 쿠버네티스는 여러 개의 스케줄러를 가질수 있다는 말이다.
- 파드를 만들거나 배치할 때 쿠버네티스에게 트정 스케줄러가 파드를 지정하도록 지시할 수 있다.
- 스케줄러가 여러 개일 경우 반드시 이름이 달라야한다.
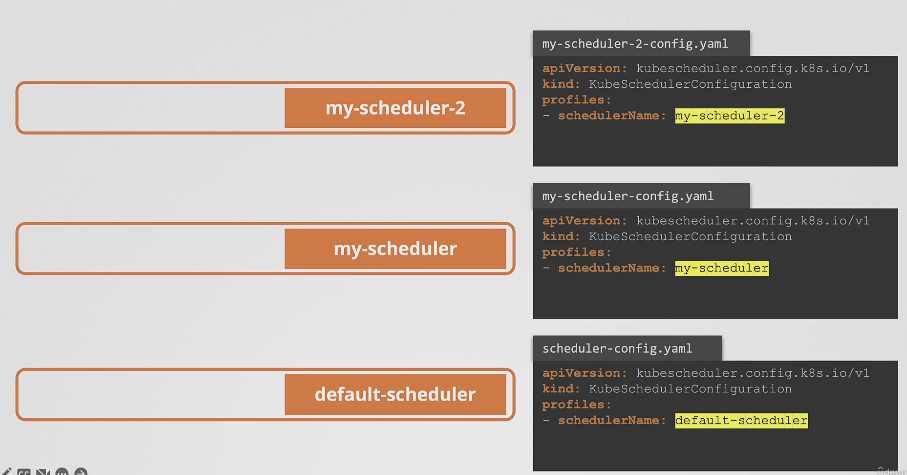
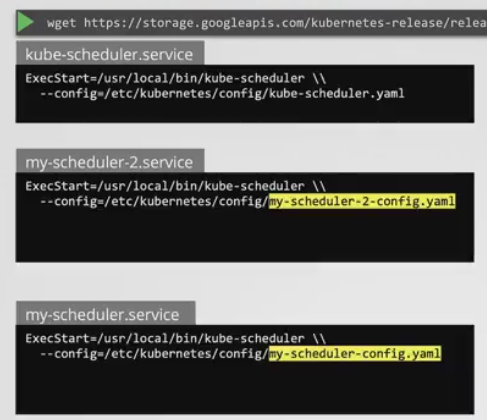
- 위와 같은 방식으로 config 파일을 따로 구성해 스케줄러를 생성할 때 각각의 config 파일을 사용하도록하면 각기 다른 스케줄러를 사용할 수 있다.
- 대부분의 경우 사용자 지정 스케줄러를 이렇게 배포하지는 않는다.
- 왜냐면 kubeadm 배포에선 모든 컨트롤 플레인의 구성 요소가 쿠버네티스 클러스터 안에서 파드로 또는 디플로이먼트로 실행되기 때문에
- 여러 개의 스케줄러를 생성하는 경우 leaderElection 옵션이 중요하다.
- 그렇다면 사용자 지정 스케줄러는 어떻게 사용하는가?
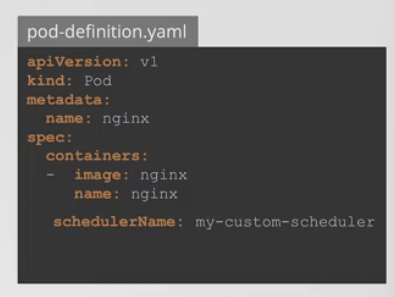
- schedulerName 필드를 이용해서 새 스케줄러의 이름을 명시해주면 된다.
- 파드가 만들어지면 알맞은 스케줄러가 선택되고 스케줄링 과정이 잘 진행된다.
- 어떤 스케줄러가 특정 파드의 스케줄링을 맡았는지 어떻게 아는가?

- kubectl get events -o wide 명령어를 이용해서 SOURCE 항목을 참조하면된다.

- kubectl logs 명령어를 이용해서 스케줄러의 로그를 확인할 수도 있다.
Configuring Scheduler Profile
- 먼저 스케줄러가 어떻게 작동하는지 복습이 필요하다.
- 파드를 생성한다고 가정했을 때 리소스 Requirements 가 CPU 10인 경우 모든 노드에서 사용 가능한 CPU를 비교한 후 10을 수용할 수 있는 노드에 스케줄링이 된다.
- 근데 해당 파드뿐만 아니라 여러 개의 파드가 동시간 대에 생성될 것이다.
- 그래서 가장 먼저 일어나는 일은 Scheduling Queue에 생성하고자 하는 파드가 들어가는 것이다.
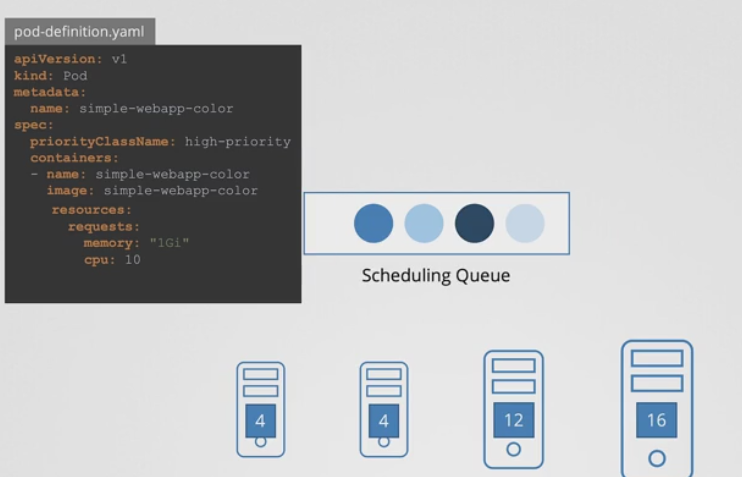
- 위와 같은 경우 파드에 따라 이미 우선순위가 정해져 있다.
- priorityClassName : high-priority 를 보면 알 수 있다.
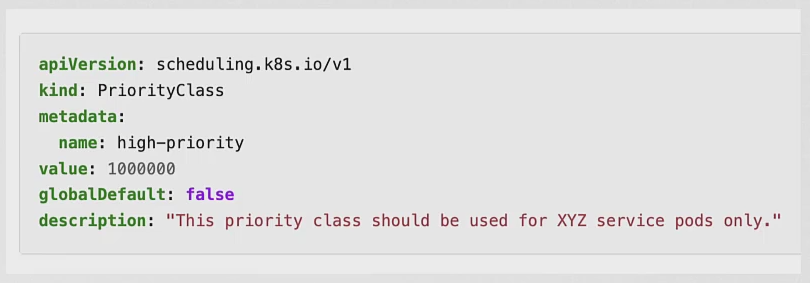
- 우선 순위 클래스는 위와 같이 생성할 수 있고 파드에서 이를 참조할 때는 필드를 입력하고 name 값을 넣어서 파드를 생성해주면 된다.
- 그럼 아래 그림과 같이 파드 우선순위가 변경되게 된다.

- 이 스케줄링이 끝나고 나면 필터 단계에 들어가게된다.

- 파드를 실행할 수 없는 노드는 이 단계에서 걸러지게된다.
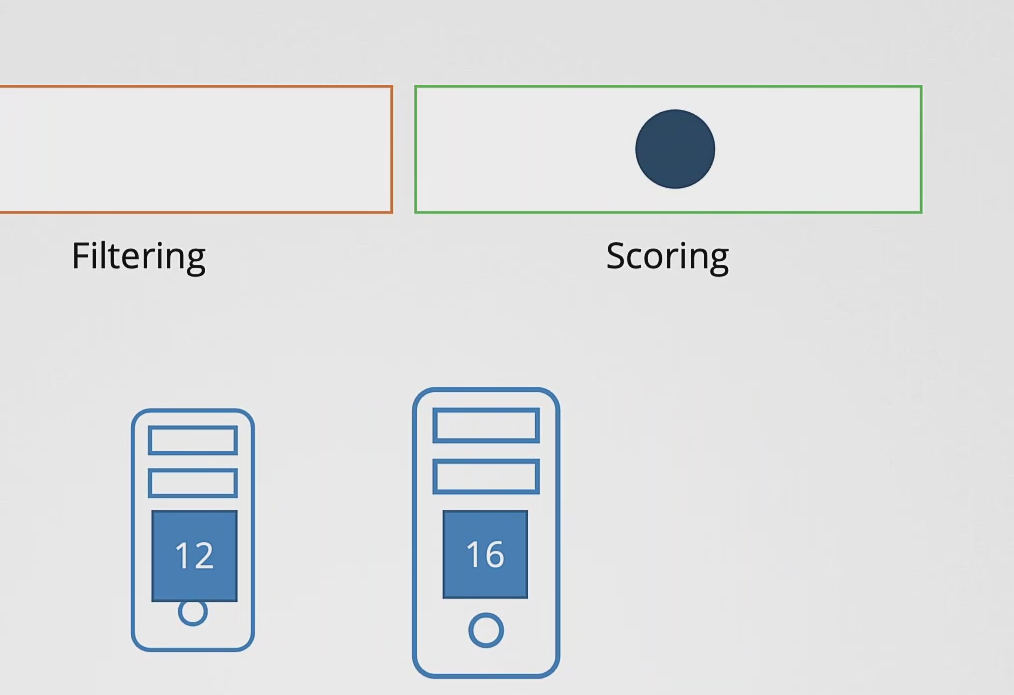
- 필터링 단계를 거치고 나면 4개의 노드에서 2개의 노드가 남게 되는 데 4개 노드 중 하나로 파드가 할당되기 위해서 점수를 매겨야한다. 이게 Scoring 단계에서 하는 일이다.
- 스케줄러는 각 노드에 남은 CPU 공간을 근거로 점수를 매긴다.
- 결국 16이라는 공간이 남은 노드가 더 높은 점수를 받게 되고 바인딩 단계로 넘어간다.
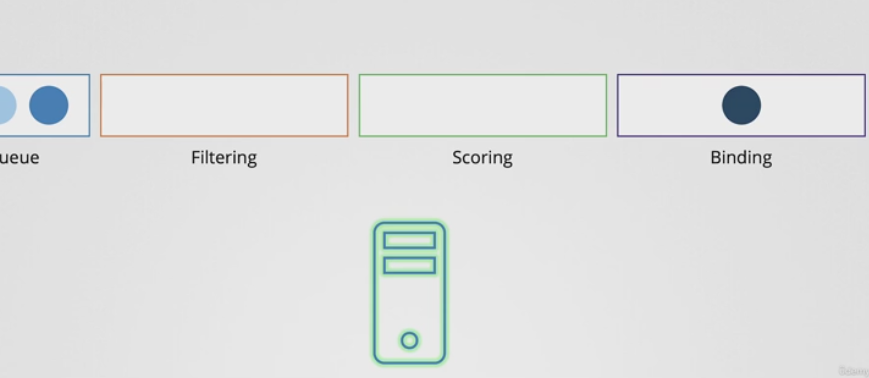
- 이 모든 작업은 특정 플로그 인으로 이루어진다.
- 예를 들어 스케줄링 큐에서 파드를 분류하는 우선순위 플러그인은 파드에서 우선순위로 설정된 기준에 따라 순서대로 정렬하는 것이다.
- 위와같은 작업을 진행하기 위해서는 각 단계별로 플러그인이 있어야한다.
- 스케줄링 큐에서 파드를 분류하는 우선순위 플러그인이 있었기 때문에 해당 기능이 가능했던 것이다.

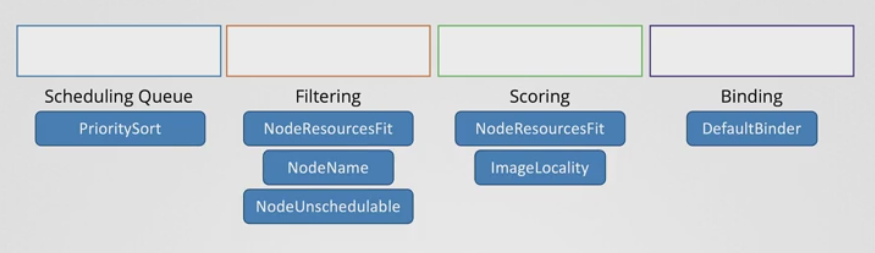
- 위와 같이 각 단계 별로 플러그인이 있음
- 쿠버네티스는 확장성이 뛰어나서 어떤 플러그인을 어디에 둘지 커스터마이징 할 수 있고 자신만의 플러그인을 작성해서 여기에 둘 수 있다.
- Extension Points 를 이용해서 그것을 달성할 수 있다.
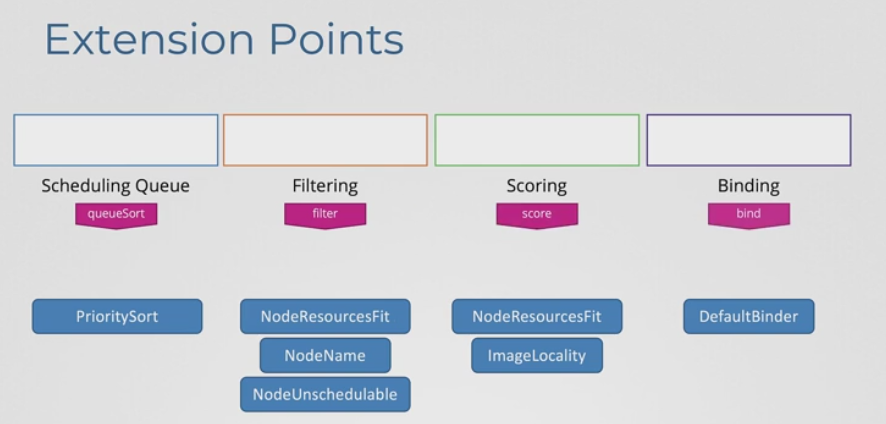
- 각 단계마다 플러그인이 열결될 수 있는 Extension Points가 있다.
- 저 Extension Points 는 사실 Pre 단계와 Post 단계도 있다.
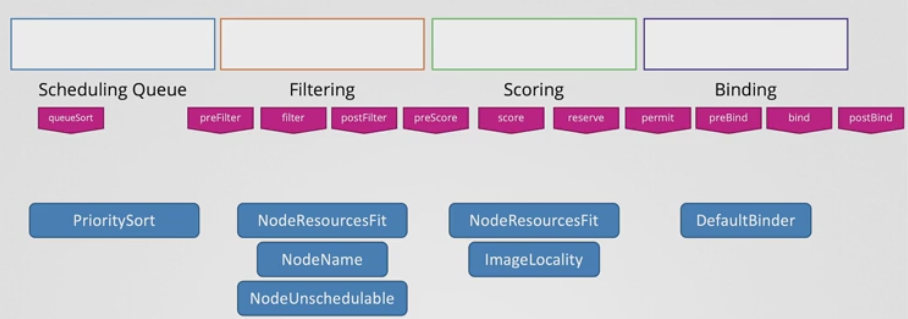
- 이런 식으로 Filtering, Scoring, Binding 단계에는 각각의 단계 이외에도 Pre post 단계가 있다.
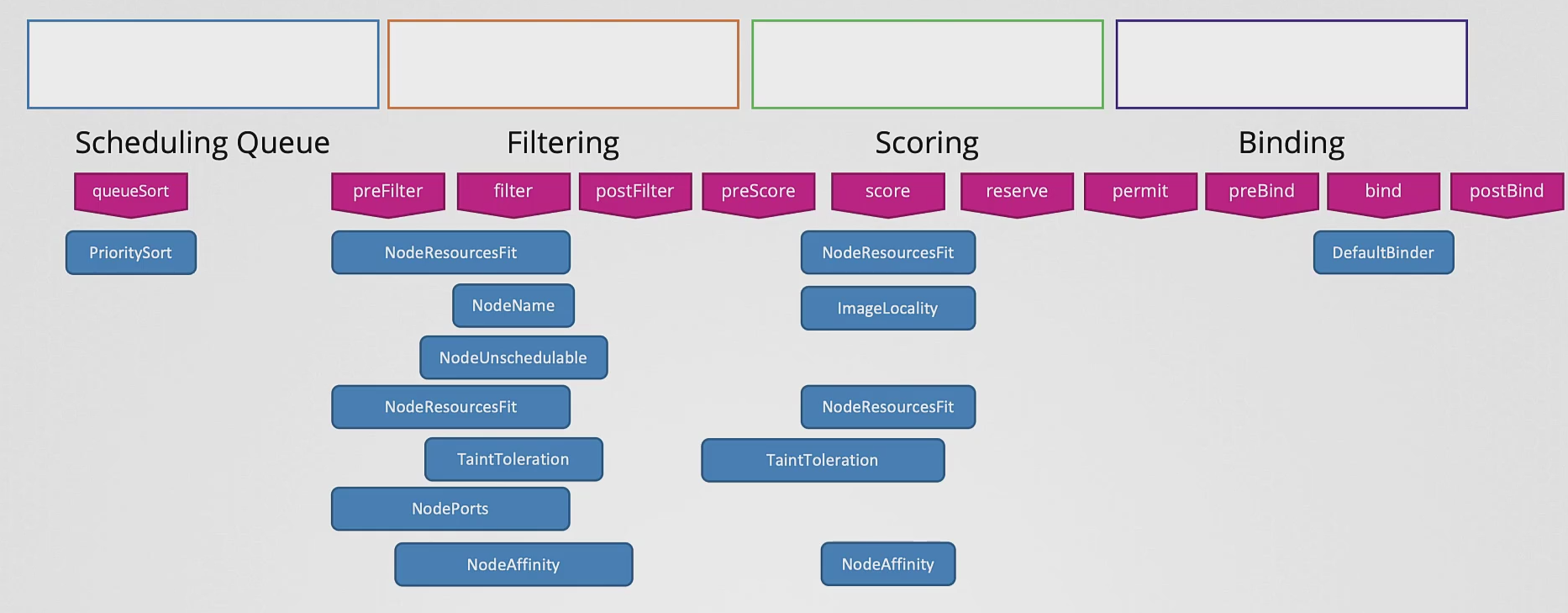
- 또한 일부 플러그인들은 한 포인트에만 있는게 아니고 여러 포인트에 걸쳐 있을 수 있다.
- 그렇다면 이를 어떻게 사용하는가?
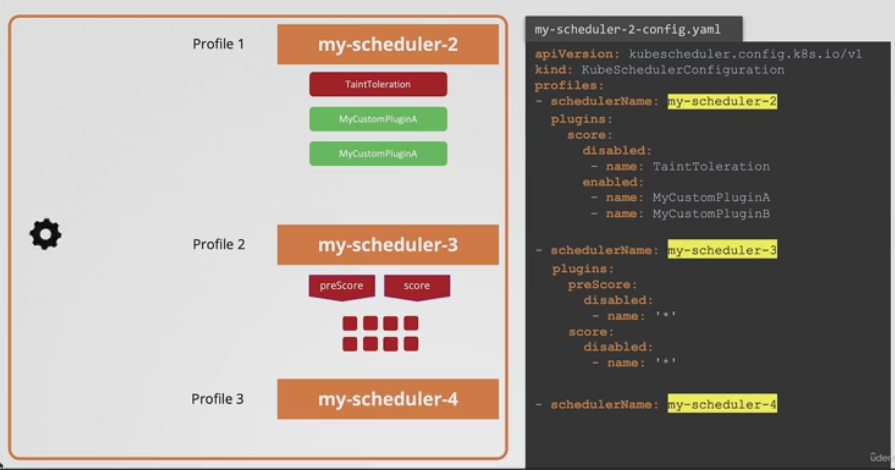
- 위와 같이 config 파일 내부에 schedulerName과 같이 plugins 필드를 생성해서 우리가 원하는 방식으로 플러그인을 구성할 수 있다.
- 파드에서 새로 구성한 Custom Scheduler를 사용하기 위해서는 아래와 같이 사용하면 된다.
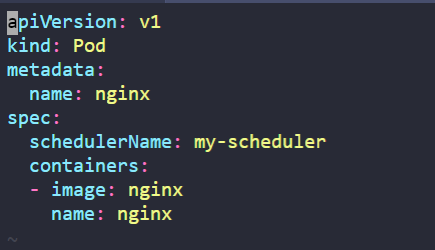
- schedulerName 을 .spec에 정의해주면 됨
[참조] :
https://www.udemy.com/course/certified-kubernetes-administrator-with-practice-tests/
반응형
'자격증 > Kubernetes CKA' 카테고리의 다른 글
| [CKA] Practice Test - Labels and Selectors (0) | 2023.12.02 |
|---|---|
| [CKA] Practice Test - Manual Scheduling (0) | 2023.12.02 |
| [CKA] Practice Test - Imperative commands (0) | 2023.11.30 |
| [CKA] Practice Test - Service (0) | 2023.11.30 |
| [CKA] Practice Test - Namespace (0) | 2023.11.30 |