
개요
쉘 스크립트 또는 명령어를 수행할 때 나오는 출력 결과를 변형해야할 일이 있다. 그런 경우 사용하면 좋은 명령어들을 정리해보고자 한다.
명령어
tr
지정한 문자를 변환하거나 삭제하는 명령어이다.
tr [OPTION]... SET1 [SET2]
# 주요 옵션
-d : SET1 에서 지정한 문자를 삭제합니다.
-s : SET2 에서 반복되는 문자를 삭제합니다.
-t : SET1을 SET2의 길이로 자릅니다.
-c : SET1을 제외한 나머지를 SET2로 치환한다.
# SET에 들어갈 수 있는 문자
a-z
a 부터 z 까지의 문자를 변형하고 싶다면 이렇게 사용해도 된다.
[:class:]
특정 class를 이용해서 특수한 형태를 지정할 수 있음. class는 아래와 같음
[:alnum:] : 알파벳 + 숫자
[:alpha:] : 알파벳
[:digit:] : 숫자(10진수)
[:xdigit:] : 숫자(16진수)
[:lower:] : 알파벳(소문자)
[:upper:] : 알파벳(대문자)
[:blank:] : whitespace 문자(공백)
[:space:] : 공백 + newline
[:special:] : 특수문자# 주로 사용하는 명령어 또는 예시
# d 옵션을 이용해서 j 를 삭제하기
$ echo 'jewon is good' | tr -d 'j'
ewon is good
# j 를 b로 변환하기
$ echo 'jewon is good' | tr 'j' 'b'
bewon is good
# s 옵션을 이용해서 중복되는 문자를 하나로 압축하기
$ echo 'jewon is good' | tr -s 'o'
jewon is god
# c 옵션을 이용해서 g, o, o, d 를 제외한 나머지를 j로 변경하기
$ echo 'jewon is good' | tr -c 'good' 'j'
jjjojjjjjgoodj
# digit과 d 옵션을 이용해 숫자 삭제하기
$ echo 'jewon is good123' | tr -d [:digit:]
jewon is good여러가지 사용 방법이 있겠지만 특정 숫자를 없애거나 알파벳을 없애던지 원하는 위치만큼 자르거나 변형하는 등의 용도로 사용했던 것 같다.
[참조] :
https://velog.io/@baekrang256/Linux-command-tr
jq
json 형식의 파일을 출력하여 형식을 변경하거나 원하는 key 값 또는 value 값을 추출하기 위해 사용함
NAME jq - Command-line JSON processor
SYNOPSIS jq [options...] filter [files...]
# 주요 옵션
-c : 출력 형식을 사용자 친화적으로 표시하지 않는 옵션. 조금 더 compact 하게 표현한다.
-n : 입력을 전혀 읽지 않습니다. 대신 null을 입력으로 사용하여 필터를 한 번 실행합니다. 이는 jq를 간단한 계산기로 사용하거나 처음부터 JSON 데이터를 구성할 때 유용합니다.
-e : 마지막 출력 값이 false도 아니고 null도 아닌 경우 0, 마지막 출력 값이 false이거나 null인 경우 1, 유효한 결과가 생성되지 않은 경우 4로 jq의 종료 상태를 설정합니다. 일반적으로 사용 문제나 시스템 오류가 있는 경우 2, jq 프로그램 컴파일 오류가 있는 경우 3, jq 프로그램이 실행된 경우 0으로 종료됩니다. 종료 상태를 설정하는 또 다른 방법은 내장 함수인 halt_error를 사용하는 것입니다.
-s : 입력의 각 JSON 객체에 대해 필터를 실행하는 대신 전체 입력 스트림을 큰 배열로 읽고 필터를 한 번만 실행합니다.
-r : 이 옵션을 사용하면 필터의 결과가 문자열인 경우 따옴표로 묶인 JSON 문자열로 서식을 지정하지 않고 표준 출력에 직접 기록됩니다. 이 옵션은 jq 필터가 JSON 기반이 아닌 시스템과 대화하도록 만드는 데 유용할 수 있습니다.
-R : 입력을 JSON으로 구문 분석하지 마세요. 대신 각 텍스트 줄이 문자열로 필터에 전달됩니다. 슬러프와 결합하면 전체 입력이 하나의 긴 문자열로 필터에 전달됩니다.
-C : 기본적으로 jq는 JSON 출력을 사용자 친화적으로 출력합니다. 이 옵션을 사용하면 각 JSON 객체를 한 줄에 배치하여 보다 간결한 출력을 얻을 수 있습니다.
-M : 기본적으로 jq는 터미널에 쓰는 경우 컬러 JSON을 출력합니다. C를 사용하여 파이프나 파일에 쓰는 경우에도 색상을 출력하도록 강제할 수 있으며, -M으로 색상을 비활성화할 수 있습니다. NO_COLOR 환경 변수가 비어 있지 않으면 jq는 기본적으로 컬러 출력을 비활성화하지만 -C로 활성화할 수 있습니다. 색상은 JQ_COLORS 환경 변수를 사용하여 구성할 수 있습니다
-S : 키가 있는 각 객체의 필드를 정렬된 순서대로 출력합니다.# 주로 사용하는 명령어 또는 예시
# r 옵션을 이용해서 원하는 출력값만 표시
~$ cat test.json | jq -r '.id' # 기본적으로 출력값은 아래와 같이 "" 에 쌓여져 있는데 r 옵션을 사용하면 값만 출력된다.
1
~$ cat test.json | jq '.id'
"1"
# keys 를 이용해서 key 만 출력하기
~$ cat test.json | jq 'keys'
[
"id",
"name"
]
~$ cat test.json
{"id": "1", "name": "jewon"}
# sort_by를 이용해서 특정 key 기준으로 정렬하기
~$ cat test1.json | jq
[
{
"id": "1",
"name": "jewon"
},
{
"id": "4",
"name": "nowon"
},
{
"id": "2",
"name": "aden"
}
]
~$ cat test1.json | jq 'sort_by(.id)' # id를 기준으로 정렬하도록 했고, 기본 출력 값에서 id 숫자를 기준으로 정렬했음을 알 수 있다.
[
{
"id": "1",
"name": "jewon"
},
{
"id": "2",
"name": "aden"
},
{
"id": "4",
"name": "nowon"
}
]
# | (파이프)를 이용해서 출력 값 재정의
~$ cat test1.json | jq '.'
[
{
"id": "1",
"name": "jewon"
},
{
"id": "4",
"name": "nowon"
},
{
"id": "2",
"name": "aden"
}
]
~$ cat test1.json | jq '.[1] | .name' # 기존 리눅스의 파이프와 유사하게 사용 가능하다. .[1] 을 통해 id 4 name nowon 을 출력하고 .name을 이용해서 name만 출력한 결과물이다.
"nowon"
# 자유롭게 값 출력하기
~$ cat test1.json | jq -c '.[0].id, .[1].id' # , (콤마) 로 구분해서 값을 자유롭게 출력할 수 있다.
"1"
"4"
~$ cat test1.json | jq '.[0].id, .[1].name'
"1"
"nowon"주로 curl 로 json 데이터를 받아와서 -r 옵션을 이용해 원하는 출력값만 사용했던 것 같다. 근데 여러가지 옵션을 이용해서 다양하게 사용 가능하고 파이프나 정규표현식 비슷하게 값을 생각보다 자유도 높게 변경할 수 있는 듯 해서 다른 옵션도 많이 찾아봐야겠다고 생각했다. 주로 사용할 것들은 위와 같다고 생각이 든다.
[참조] :
https://linuxcommandlibrary.com/man/jq
cut
문자열을 특정 위치에서 특정 위치까지 짤라서 출력하거나, 원하는 구분자를 이용해 특정 문자를 출력하기위해 사용함.
Usage: cut OPTION... [FILE]...
# 주요 옵션
-b, --bytes=LIST select only these bytes
-c, --characters=LIST select only these characters
-d, --delimiter=DELIM use DELIM instead of TAB for field delimiter
-f, --fields=LIST select only these fields; also print any line that contains no delimiter character, unless the -s option is specified
-n (ignored)
--complement complement the set of selected bytes, characters or fields
-s, --only-delimited do not print lines not containing delimiters
--output-delimiter=STRING use STRING as the output delimiter the default is to use the input delimiter
-z, --zero-terminated line delimiter is NUL, not newline# 주로 사용하는 명령어 또는 예시
# c 옵션을 사용해서 특정 문자만 출력하기
~$ cat test.json
{"id": "1", "name": "jewon"}
~$ cat test.json | cut -c 3
i
~$ cat test.json | cut -c 1,5
{"
# b 옵션을 이용해서 특정 바이트만 출력하기
~$ cat test2.json
[{"id": "1", "name": "jewon"},
{"id": "4", "name": "nowon"},
{"id": "2", "name": "aden"}]
~$ cat test2.json | cut -b 1-5
[{"id
{"id"
{"id"
~$ cat test2.json | cut -b 2-19
{"id": "1", "name"
"id": "4", "name":
"id": "2", "name":
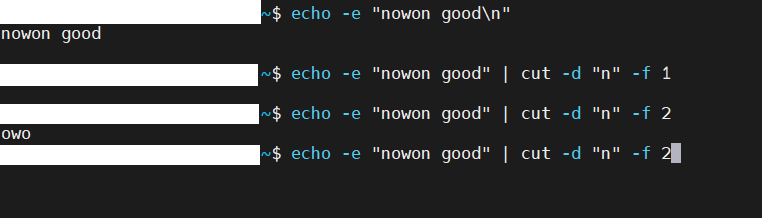
# d 옵션과 f 옵션을 이용해 구분자를 설정하고 해당 구분자로 나뉘어진 영역을 출력하기
~$ cat test2.json | cut -d ',' -f 1
[{"id": "1"
{"id": "4"
{"id": "2"
~$ cat test2.json | cut -d ',' -f 2
"name": "jewon"}
"name": "nowon"}
"name": "aden"}]
# --complement 옵션을 사용해 내가 선택한 부분 외의 부분을 출력한다. 여집합이라 생각하면 편할듯
~$ cat test2.json | cut -d ',' -f 2 --complement
[{"id": "1",
{"id": "4",
{"id": "2"
# s 옵션을 이용해 내가 선택한 구분자가 있는 행만 출력 결과에 포함한다.
~$ cat test3.json
[{"id": "1", "name": "jewon"},
{"id": "4", "name": "nowon"},
{"id": "2", "name": "aden"}]
nowon9159
~$ cat test3.json | cut -d ',' -f 1 -s
[{"id": "1"
{"id": "4"
{"id": "2"보통 문자열을 특정 문자로 구분지어 해당 내용만 출력하기 위해서 사용했던 것 같다. d 옵션을 주로 많이 사용했었는데 s 옵션이나 --complement를 이용해 더 잘 사용할 수 있지 않았나한다.
[참조] :
https://rhrhth23.tistory.com/106
https://phoenixnap.com/kb/linux-cut
sed
출력 결과를 확인해 특정 문자열을 찾아서 해당 문자열을 변경하거나 제거하거나, 특정 문자열을 찾아서 해당 문자열의 행을 제거하는 등의 기능도 가능하다.
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...
# 주요 옵션
-e : 다중 필터를 걸어서 다중 편집을 가능하게 한다. 2개 이상의 값을 편집할 때 유용하게 쓰임
-n : 전체 출력을 생략하고 패턴이 일치하는 원하는 부분만 출력할 수 있게한다.
-i : 수정한 내용으로 파일 덮어쓰기
# sed 's/~~/#' #에 들어가는 치환 플래그
g : 치환이 전체 행에 적용된다.
p : 행을 출력한다.
w : 치환 후 해당하는 파일에 행을 입력한다.# 주로 사용하는 명령어 또는 예시
# sed '/a/d' file 를 이용해서 a가 포함된 행 삭제
~$ cat test3.json
[{"id": "1", "name": "jewon"},
{"id": "4", "name": "nowon"},
{"id": "2", "name": "aden"}]
nowon9159
~$ cat test3.json | sed '/jewon/d'
{"id": "4", "name": "nowon"},
{"id": "2", "name": "aden"}]
nowon9159
# sed 's/a/d/g' file 를 이용해서 a가 포함된 행을 d로 치환하기
~$ cat test3.json | sed 's/jewon/handsome/g'
[{"id": "1", "name": "handsome"},
{"id": "4", "name": "nowon"},
{"id": "2", "name": "aden"}]
nowon9159
# sed '^$/d' file 를 이용해서 공백의 행을 삭제하기
~$ cat test4.json
{"id": "1", "name": "jewon"}
{"id": "2", "name": "nowon"}
~$ cat test4.json | sed '/^$/d'
{"id": "1", "name": "jewon"}
{"id": "2", "name": "nowon"}
# sed 's/ //g' 를 이용해서 행에 있는 스페이스 삭제하기
~$ cat test4.json | sed 's/ //g'
{"id":"1","name":"jewon"}
{"id":"2","name":"nowon"}
# -n 옵션을 이용해서 특정 위치의 행만 출력
~$ cat test_sed.txt
This is test for sed
Hello world
I just practicing sed for writing blog post
~$ sed -n 1,2p test_sed.txt
This is test for sed
Hello world
# -e 옵션을 이용해서 다중 행 출력
# sed 'd' 를 이용해서 특정 행 제거
~$ sed '1,2d' test_sed.txt
I just practicing sed for writing blog post
# | 을 이용해 두가지의 값을 동시에 치환하기
~$ sed 's/test\|writing//g' test_sed.txt # test와 writing을 공백 값으로 치환해 주었다. # | 파이프 사용시 \ 역슬래시를 꼭 붙여줘야 한다.
This is for sed
Hello world
I just practicing sed for blog post
# 행별로 빈 행을 추가하기
~$ sed 'a\\' test_sed.txt
This is test for sed
Hello world
I just practicing sed for writing blog post
# i 옵션으로 원본 파일 덮어쓰기
~$ sed -i 's/test/good/g' test_sed.txt
~$ cat test_sed.txt
This is good for sed
Hello world
I just practicing sed for writing blog post
good
# c\ 를 이용해서 행의 내용을 새로운 내용으로 치환
~$ sed -n 'c\ggg\' test_sed.txt
ggg
ggg
ggg
ggg
# i\ 를 이용해서 행 위에 새로운 행을 추가
~$ sed 'i\ggg\' test_sed.txt
ggg
This is good for sed
ggg
Hello world
ggg
I just practicing sed for writing blog post
ggg
good
# w 치환 플래그 사용법
~$ cat test_sed.txt
This is good for sed
Hello world
I just practicing sed for writing blog post
good
~$ sed -e 's/good/test/w testtest.txt' test_sed.txt
This is test for sed
Hello world
I just practicing sed for writing blog post
test
~$ cat testtest.txt
This is test for sed
testsed 's/asdf/qwer/g' 등의 형식으로 많이 사용되며 주로 문서 내에서 특정 문자열을 변경하거나, 특정 행을 삭제하는 용도로 많이 사용했던 것 같다. sed -i 옵션을 이용해서 덮어쓰기를 해주는 용도로 사용하면 Userdata 기반의 자동화를 진행할 때나 일반적으로 자동화를 진행할 때 특정 텍스트 파일의 내용을 변경하는 용도로 매우 용이하게 사용했던 것 같다.
[참조] :
https://velog.io/@inhwa1025/Linux-SED-%EB%AA%85%EB%A0%B9%EC%96%B4-%EC%82%AC%EC%9A%A9%EB%B2%95
awk
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
# 주요 옵션
awk [OPTION...] [awk program] [ARGUMENT...]
OPTION
-F : 필드 구분 문자 지정.
-f : awk program 파일 경로 지정.
-v : awk program에서 사용될 특정 variable값 지정.
awk program
-f 옵션이 사용되지 않은 경우, awk가 실행할 awk program 코드 지정.
ARGUMENT
입력 파일 지정 또는 variable 값 지정.기본적으로 awk는 특정 패턴과 액션을 통해서 동작한다.
- awk pattern {action}
위와 같은 형식으로 많이 사용됨
또한 awk는 문자를 열(필드)과 행(레코드)으로 구분지어 인식할 수 있다.
~$ awk '{print}' test_awk.txt
category total used free shared buff/cache available
Mem: 3059804 55328 2919800 68 84676 2882664
Swap: 1048576 0 1048576이런 형태로 출력이 가능하며 열 별로 출력하고 싶다면
~$ awk '{print $2}' test_awk.txt
total
3059804
1048576아래와 같은 명령어 형태로 입력하면 된다. print $n n은 넘버를 입력하면 해당 열이 출력된다.
# 주로 사용하는 명령어 또는 예시
# print를 이용해서 전체 출력
~$ awk '{print}' test_awk.txt
category total used free shared buff/cache available
Mem: 3059804 55328 2919800 68 84676 2882664
Swap: 1048576 0 1048576
# $n을 이용해서 특정 행만 출력
~$ awk '{print $2}' test_awk.txt
total
3059804
1048576
# 원하는 특정 문자열을 출력 결과에 포함하여 출력
~$ awk '{print "good jewon " $2}' test_awk.txt
good jewon total
good jewon 3059804
good jewon 1048576
# 특정 문자열을 검색하여 해당하는 레코드만 출력
~$ awk '/Mem/' test_awk.txt
Mem: 3059804 55328 2919800 68 84676 2882664
# 특정 필드 값을 비교해 일치하는 값이 있는 경우에만 해당 레코드를 출력하기
~$ cat test_awk1.txt
total used free shared buff/cache available
Mem: 2 0 2 0 0 2
Swap: 1 0 1
~$ awk '$2 == 2 {print $2}' test_awk1.txt
2
~$ awk '$2 == 2 {print $3}' test_awk1.txt
0
# 특정 필드 값을 모두 더한 값을 출력하기
~$ awk '{sum += $2} END {print sum}' test_awk1.txt
3
# 쉼표를 구분으로 여러 항목을 출력하는 결과
~$ awk '{print $1, $2, $3}' test_awk.txt
category total used
Mem: 3059804 55328
Swap: 1048576 0
# -F 옵션으로 필드 구분자 변경하기
~$ cat test_awk.txt
category total used free shared buff/cache available
Mem: 3059804 55328 2919800 68 84676 2882664
Swap: 1048576 0 1048576
~$ awk -F ':' '{print $2}' test_awk.txt
3059804 55328 2919800 68 84676 2882664
1048576 0 1048576위에서 알 수 있듯이 여러 연산자 또는 조건식을 사용할수도 있다.
사용 가능한 연산자
- +
- -
- <
- <=
- !=
- ==
- >
- >=
- ~
- !-
- in array
- &&
- ||
- A1?A2:A3
- +=
- -=
- *
- /
- %
- ++E
- --E
- E++
- E--
- E^E
awk 는 기본적으로 제공되는 변수가 있다.
- NF : 레코드에 있는 필드 수
- NR : 현재 레코드의 번호
- FILENAME : 현재 처리중인 입력 파일의 이름
- FS : 필드 구분자
- RS : 구분 기호를 기록한다.
- OFS : 출력 필드 구분자
- ORS : 출력 레코드 구분 기호
- ARGC : ARGV 배열 요소의 개수
- ARGV : 커맨드 라인 argument에 대한 배열
- CONVFMT : 문자열을 숫자로 변경할 때 사용할 형식 ex) "%.6g"
- ENVIRON : 환경변수에 대한 배열
- FNR : 현재 파일에서 현재 레코드의 순서 값
- OFMT : 문자열을 출력할 때 사용할 형식
- RLENGTH : match 함수에 의해 매칭된 문자열의 길이
- RSTART : match 함수에 의해 매칭된 문자열의 시작 위치
위와 같은 변수를 사용할 수도 있다.
또 BEGIN과 END 패턴을 사용할수도 있다.
BEGIN의 경우 레코드를 처리하기 전에 BEGIN에 지정된 액션을 실행한다. 그리고 END의 경우 모든 레코드를 처리하고 END에 지정된 액션을 실행한다.
# BEGIN과 END 패턴 사용하기
~$ awk 'BEGIN {print "test BIGIN - print total and used"} {print $2, $3} END {print "Done."}' test_awk.txt
test BIGIN - print total and used
total used
3059804 55328
1048576 0
Done.위와 같이 BEGIN을 이용해서 어떤 내용을 출력할 것인지 END를 이용해서 어떤 내용이 출력되고 나서 특정 내용을 집어넣고 싶을때 사용 가능하다.
이 외에도 C언어 기반으로 출력값(print 문)을 구할 수 있다고 하니 필요에 의해 잘 구성하여 작성하는 게 좋겠다.
[참조] :
https://recipes4dev.tistory.com/171
https://jjeongil.tistory.com/1937
기타
${String:Position:length}
# 변수 선언 후 string 조작
~$ export string=abcdefg
~$ echo ${string}
abcdefg
~$ echo ${string:0}
abcdefg
~$ echo ${string:1}
bcdefg
~$ echo ${USER}
nowon9159
~$ echo ${USER:0:3}
now
~$ echo ${USER:1:3}
owoString은 원하는 변수가 될 것이다. 해당 문자열을 기반으로 텍스트를 새로 추출해내는 게 ${String:Position:length}이다.
Position은 추출을 시작하는 위치라고 생각하면 된다. 위와 같이 예를들어 nowon9159 가 있고, ${USER:0} 으로 지정을 한다면 처음부터 끝까지 출력을 하는 것이다.
length는 텍스트 길이의 개수라고 생각하면 된다. 예를들어 nowon9159가 있고 ${USER:0:3} 이라고 하면 now가 추출되고 ${USER:1:3} 이라고 하면 owo가 출력될 것이다.
문자열 길이 출력
다양한 방법이 있는데 아래와 같다.
- ${#string}
- expr length $string
- expr "$string" : '.*'
~$ echo $USER
nowon9159
~$ echo ${#USER}
9
~$ expr length $USER
9
~$ expr "$USER" : '.*'
9[참조] :
https://wiki.kldp.org/HOWTO/html/Adv-Bash-Scr-HOWTO/string-manipulation.html
https://wiki.kldp.org/HOWTO/html/Adv-Bash-Scr-HOWTO/index.html
'서버 관리 > 운영체제' 카테고리의 다른 글
| [Linux] 네트워크 관련 명령어 정리 (0) | 2024.05.08 |
|---|---|
| [Linux] 표준 입력, 표준 출력, 표준 에러란? (0) | 2023.09.20 |