
반응형

Troubleshooting
Application Failure
- 강의에선 예시를 들어 설명했다. 웹 서버와 데이터베이스 서버가 있는 2계층 애플리케이션이 있다.
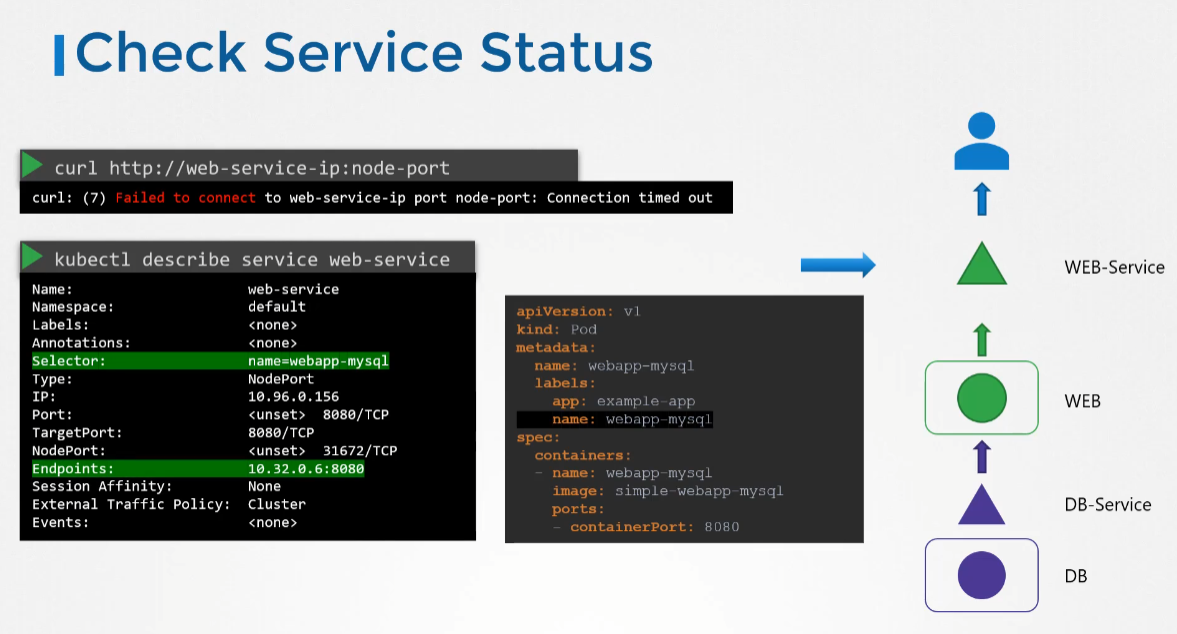
- 데이터베이스 파드는 데이터베이스 응용 프로그램을 호스팅하고 데이터베이스 서비스를 통해 웹 서버에 서비스를 제공한다.
- 웹 서버는 웹 팟에 호스팅되며 웹 서비스를 통해 사용자에게 서비스를 제공한다.
- 문제의 원인을 찾을 때까지이 맵의 모든 객체와 링크를 확인하는 것이 좋다고 한다.
- 웹 애플리케이션인 경우 curl을 사용하여 노드 포트의 웹 서버에 액세스할 수 있는지 확인한다.
- 다음으로 서비스를 확인한다. 웹 파드에 대한 엔드포인트가 있는 지 확인한다.
- 엔드포인트가 없다면 서비스에 구성된 셀렉터가 파드에 구성된 것과 일치하는지 확인한다.

- 그 다음 파드 자체를 확인하고 실행 중인지 확인한다. 파드의 상태 및 재시작 회수를 확인해 상태를 확인할 수 있다.
- describe 명령을 사용하여 팟과 관련된 이벤트를 확인한다.
- logs 명령을 사용하여 응용 프로그램의 로그를 확인한다.
- 파드가 장애로 인해 다시 시작되는 경우 현재 컨테이너의 현재 버전을 실행 중인 현재 파드의 로그에는 마지막으로 실패한 이유가 표시되지 않을 수 있다. 따라서 -f 옵션을 사용해 실시간으로 지켜보고 응용 프로그램이 다시 실패할 때까지 기다리는 방법이 있다.

- 다음으로 이전과 같이 DB 서비스의 상태를 확인하고 마지막으로 DB 파드 자체를 확인한다.
- DB 파드의 로그를 확인하고 데이터베이스에서 발생한 오류를 찾아본다.
Control Plane Failure

- 먼저 클러스터의 노드 상태를 확인해 모두 건강한지 확인한다. 그리고 실행중인 파드의 상태를 확인한다.
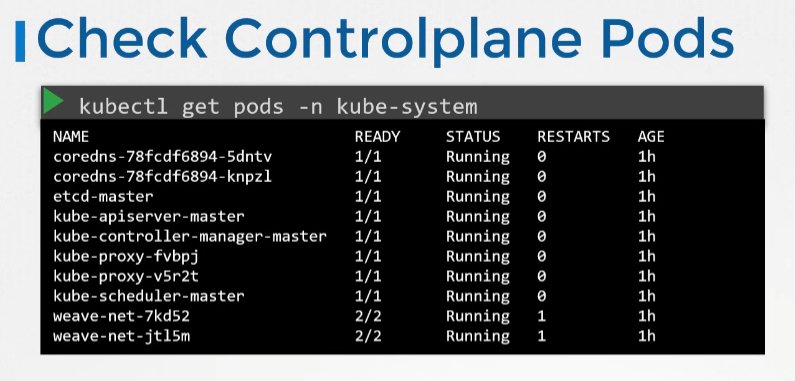
- kubeadm 도구를 사용해 배포된 클러스터의 경우 kube-system 네임스페이스 내 파드가 실행중인지 확인 가능하다.
# 마스터 노드
service kube-apiserver status
service kube-controller-manager status
service kube-scheduler status
# 워커 노드
service kubelet status
service kube-proxy status- 그 다음 마스터 노드에서 kube-apiserver. 컨트롤러 매니저 및 스케줄러의 상태를 확인하고 워커노드에서 kubelet 및 kube-proxy 서비스의 상태를 확인 해보자

- 그 다음 logs 명령어를 이용해 각 구성요소의 파드 로그를 확인한다.
- 마스터 노드에서 기본 설정된 서비스의 경우 journalctl 명령어를 이용해 kuge-apiserver의 로그를 확인 가능하다.
Worker Node Failure
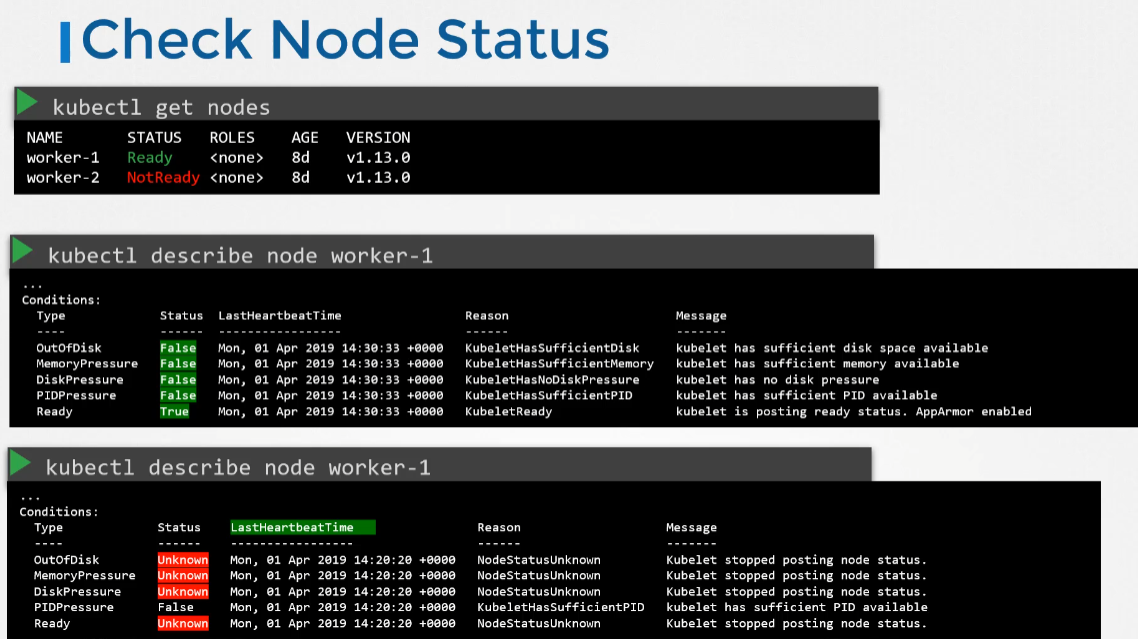
- 처음엔 클러스터의 노드 상태를 확인하는 것으로 시작한다. 노드가 준비 상태인지 아닌지를 확인한다.
- 준비 상태가 아니라면 kubectl describe node 명령을 사용해 노드에 대한 자세한 정보를 확인한다.
- 각 노드에는 노드가 왜 실패했는 지를 나타낼 수 있는 Conditions 가 있다. 상태에 따라 true, false 또는 unknown으로 표기된다.
- 노드가 디스크 공간이 부족하면 디스크 부족 플래그가 true가 된다.
- 디스크 여유 공간이 없는 경우 DiskPressure 플래그가 true로 설정된다.
- 마찬가지로 프로세스가 너무 많은 경우 PIDPressure 플래그가 true로 설정된다.
- 마지막으로 노드 전체가 건강한 경우 ready 플래그가 true로 설정된다.
- LastHeartbeatTime 필드를 확인하면 노드가 언제 망가졌는지 알 수 있다.
- 워커 노드가 마스터와 통신을 중지할 때 이러한 상태는 Unknown으로 설정된다. 이는 노드의 손실 가능성을 나타낼 수 있다. 노드가 충돌했을 때 노드 자체의 상태를 확인한다.
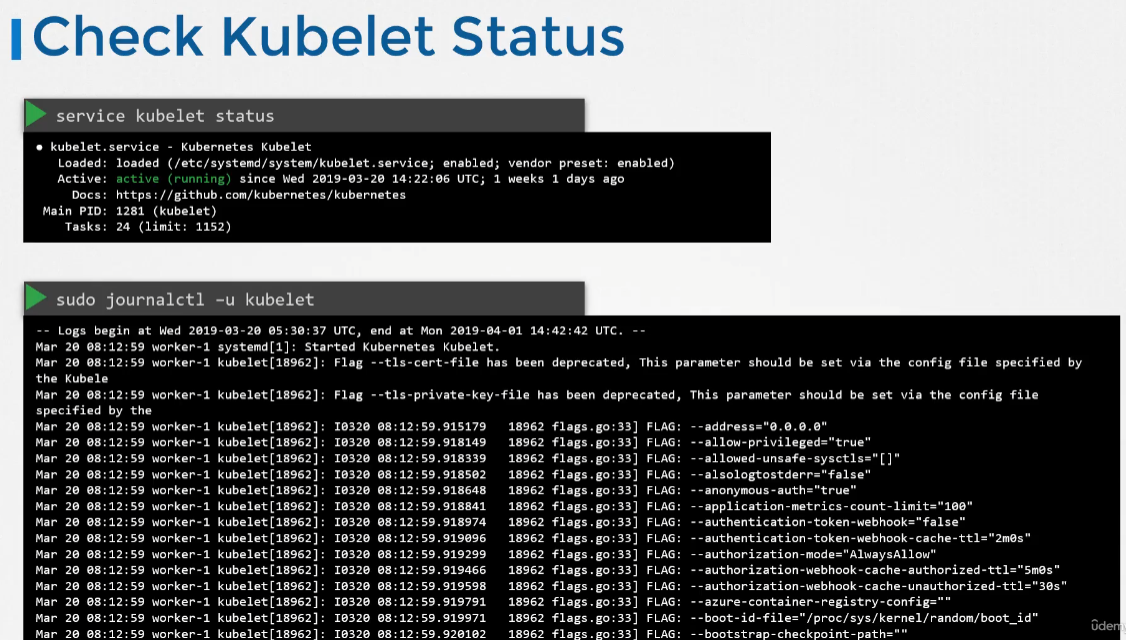
- 노드가 실패했을 때 확인해야할 사항은 top 으로 cpu memory를 확인하거나 df -h 를 이용해 디스크 공간을 확인하거나 kubelet 서비스의 상태를 확인하거나, kubelet의 시스템 로그를 확인해보는 방법이 있다.
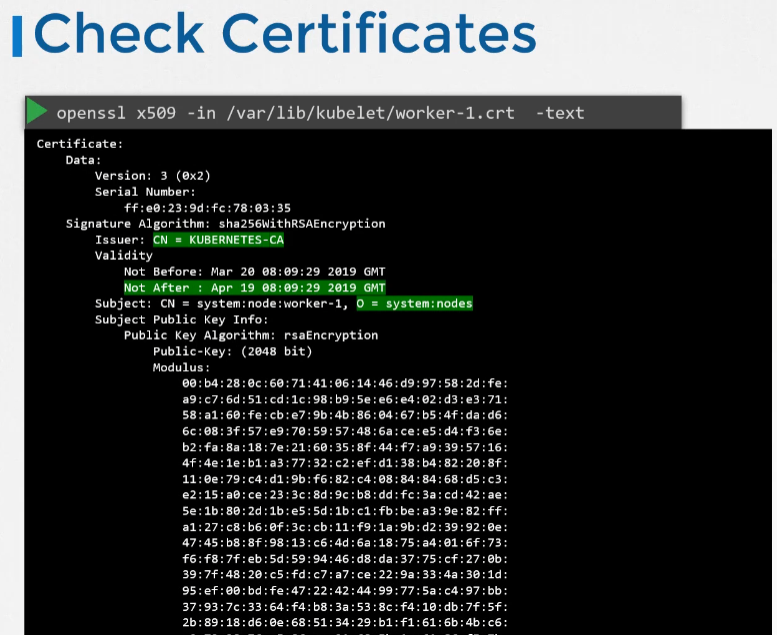
- 또한 kubelet의 인증서를 확인해 만료되지 않았는지, 올바은 그룹의 일부인지, 올바른 CA가 인증서를 발행 했는지도 확인해보면 된다.
Network Troubleshooting
DNS in Kubernetes
- 대규모 쿠버네티스 클러스터에서 CoreDNS의 메모리 사용량은 주로 클러스터의 파드 및 서비스 수에 의해 여향을 받는다.
- 다른 요인으로는 채워진 DNS answer cache와 CoreDNS 인스턴스 당 쿼리 수신 속도(QPS)가 있다.
CoreDNS를 위한 쿠버네티스 리소스
- a service account named coredns,
- cluster-roles named coredns and kube-dns
- clusterrolebindings named coredns and kube-dns,
- a deployment named coredns,
- a configmap named coredns and a
- service named kube-dns.
ConfigMap으로 정의되는 Corefile
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
CoreDNS와 관련된 트러블 슈팅 이슈
- pending 상태의 CoreDNS 파드를 발견하면 먼저 네트워크 플러그인이 설치되어 있는지 확인해라
- CoreDNS 파드는 CrashLoopBackOff 또는 Error 상태일 경우
- older 버전의 도커로 SELinux를 실행하는 노드가 있는 경우 CoreDNS 파드가 시작되지 않는 경우가 발생할 수 있다.
- 해결 방법은 Docker를 새 버전으로 업그레이드 하거나,
- SELinux를 Disable 하거나
- CoreDNS deployment의 allowPrivilegeEscalation 을 true로 수정한다.
- CoreDNS에 CrashLoopBackOff 가 발생하는 또 다른 원인은 쿠버네티스에 배포된 CoreDNS 파드가 loop를 감지할 때이다.
- 아래와 같은 해결 방법도 있다.
- kubelet 구성 yaml에 다음을 추가한다: resolvConf: <path-to-your-real-resolv-conf-file> 이 플래그는 kubelet이 대체 resolv.conf를 파드에 전달하도록 지시한다. systemd-resolved를 사용하는 시스템의 경우, 배포판에 따라 다를 수 있지만 일반적으로 /run/systemd/resolve/resolv.conf가 "실제" resolv.conf의 위치이다.
- 호스트 노드에서 로컬 DNS 캐시를 비활성화하고 /etc/resolv.conf를 원래대로 복원합니다.
- 빠른 해결 방법은 코어파일을 forward로 변경하면 된다. /etc/resolv.conf를 업스트림 DNS의 IP 주소로 바꾸면 됩니다(예: forward . 8.8.8.8. 그러나 이것은 코어DNS의 문제만 해결하며, kubelet은 계속해서 모든 기본 dnsPolicy 파드에 잘못된 resolv.conf를 전달하여 DNS를 확인할 수 없게 만든다.
- older 버전의 도커로 SELinux를 실행하는 노드가 있는 경우 CoreDNS 파드가 시작되지 않는 경우가 발생할 수 있다.
- CoreDNS 파드와 kube-dns 서비스가 정상적으로 작동한느 경우, kube-dns 서비스에 유효한 엔드포인트가 있는지 확인한다.
- kubectl -n kube-system get ep kube-dns 명령어를 사용해 서비스에 대한 엔드포인트를 확인하고, 없다면 서비스를 분석하고 올바은 셀렉터와 포트를 사용하는 지 확인한다.
Kube-Proxy
- kube-proxy는 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 노드에서 네트워크 규칙을 유지 관리한다. 이러한 네트워크 규칙은 클러스터 내부 또는 외부의 네트워크 세션에서 파드로의 네트워크 통신을 허용한다.
- kubeadm 으로 클러스터를 구성한 경우 daemonset으로 kube-proxy를 찾을 수 있다.
- kubeproxy는 각 서비스와 관련된 서비스 및 엔드포인트를 감시한다. 클라이언트가 가상 IP를 사용해 서비스에 연결하려는 경우 kubeproxy는 실제 파드로 트래픽을 전송한다.
- 만약 kubectl describe ds kube-proxy -n kube-system을 실행하면 kube-proxy 컨테이너 내에서 다음과 같은 명령으로 kube-proxy 바이너리가 실행되는 것을 확인할 수 있다.
Command:
/usr/local/bin/kube-proxy
--config=/var/lib/kube-proxy/config.conf
--hostname-override=$(NODE_NAME)- /var/lib/kube-proxy/config.conf 와 같은 구성 파일을 가져오고 호스트 이름을 파드가 실행 중인 노드 이름으로 재정의할 수 있다.
- 구성 파일에서는 ClusterCIDR, kubeproxy mode, ipvs, iptables, bindaddress, kube-config 등을 정의한다.
kube-proxy 와 관련된 트러블 슈팅 이슈
- kube-system 네임스페이스 안에 kube-proxy 파드가 실행 중인지 확인
- kube-proxy logs를 확인해라
- ConfigMap이 올바르게 정의되어 있고, kube-proxy 바이너리 실행을 위한 config file이 올바른지 확인한다.
- kube-config 라는 configmap이 있는지 확인해라
- 컨테이너 내부에서 kube-proxy 가 실행 중인지 확인해라.
# 컨테이너 내부에서 kube-proxy 가 실행 중인지 확인하는 명령어
netstat -plan | grep kube-proxy
tcp 0 0 0.0.0.0:30081 0.0.0.0:* LISTEN 1/kube-proxy
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 1/kube-proxy
tcp 0 0 172.17.0.12:33706 172.17.0.12:6443 ESTABLISHED 1/kube-proxy
tcp6 0 0 :::10256 :::* LISTEN 1/kube-proxy반응형
'자격증 > Kubernetes CKA' 카테고리의 다른 글
| [CKA] Practice Test - Env Variables (0) | 2024.01.01 |
|---|---|
| [CKA] Practice Test - Commands And Arguments (1) | 2024.01.01 |
| [CKA] Install "Kubernetes the kubeadm way" (0) | 2023.12.31 |
| [CKA] Networking - 3 (0) | 2023.12.30 |
| [CKA] Networking - 2 (1) | 2023.12.30 |