
시작하기 전
1주차 시작하고 나서지만 간단히 시작한 소감을 적어보려고 한다.
대기업이나 대규모 트래픽을 가진 기업들은 꼭 Istio를 요구 사항으로 넣는 것으로 보았다. 또한 내부 트래픽을 간단하게 전달하고 보안적 요소가 좋다는 이야기를 들은 적이 있었어서 공부해보고 싶은 주제였기도 하고, 사실 완벽하게 이 툴에 대한 이해도를 높이는 것보다 (이렇게 되려면 실무에서 사용해야 하는데 사용하고 있지 않고, 사용할 것 같지 않다) 직접 마주해보고 싶은 느낌이 강했다.
항상 정리의 글은 파란색 글씨인 인용문으로 달고자 하니 참고 바란다. 파란 글씨와 본글을 번갈아 읽으면 더 이해가 잘될것! 인용문은 링크도 있으니 참고 바란다!
1장 서비스 메시 소개하기
배경
클라우드 플랫폼이나 컨테이너 같은 신기술을 더 빠르게 활용하기 위한 방법을 모색하다 보면 과거의 문제가 증폭되는 상황을 마주하게 된다.
예를 들어 네트워크는 신뢰할 수 없으므로, 더 크고 더 분산된 시스템을 구축할 때는 네트워크가 애플리케이션 설계 고려사항의 중심이 돼야 한다.
- 애플리케이션은 재시도, 타임아웃, 서킷 브레이커 같은 네트워크 복원력을 구현해야 하는가?
- 일관된 네트워크 관찰 가능성은 어떤가?
- 애플리케이션 계층 보안은?
거대 IT 시스템에서 개발자는 중요한 자원?이므로, 이들의 시간은 비즈니스 가치를 차별화된 방식으로 전달할 수 있는 기능을 작성하는 데 사용해야 한다.
애플리케이션 네트워킹, 보안, 메트릭 수집은 필수이지만 차별화 요소는 아니다.
우리가 원하는 것은 이런 기능을 언어와 프레임워크에 구애받지 않는 방식으로 구현하고 정책으로 적용하는 것이다.
옛날의 3 Tier나 MSA를 하고 있지 않던 상황에서는 사실 애플리케이션 간의 관계만 생각하면 된다고 생각이 든다. 최근 애플리케이션의 기조는 보통 MSA로 잘게 나눠져 있는 구조다 보니 특정 애플리케이션의 경우 히스토리가 없거나 신규 프로젝트의 TF를 구성할 때 Java를 사용할 줄 아는 개발자를 채용하고 사용하면서 여러 프레임워크가 동시에 사용되는 환경도 존재한다고 알고 있다. 이런 경우 특정 애플리케이션 간의 관계 뿐 아니라 네트워크도 고려 사항에 들어가야 한다고 이해를 했다.
서비스 매시 Service Mesh
애플리케이션을 안전하고 복원력 있고 관찰 가능하고 제어할 수 있게 하는 분산 애플리케이션 네트워킹 인프라를 설명하는 데 사용한다.
서비스 메시란 데이터 플레인과 컨트롤 플레인으로 구성된 아키텍처를 말하는데, 여기서 데이터 플레인은 애플리케이션 계층 프록시를 사용해 애플리케이션 대신 네트워킹 트래픽을 관리하고 컨트롤 플레인은 프록시를 관리한다.
이를 사용하면 특정 프로그래밍 언어나 프레임워크에 의존하지 않고, 중요한 애플리케이션-네트워킹 기능을 애플리케이션 외부에서 구축할 수 있다.
Istio는 위에서 얘기한 여러 프레임워크를 사용할 경우 특정 프로그래밍 언어나 프레임워크에 의존하지 않고 애플리케이션과는 독립적으로 네트워킹 기능을 애플리케이션 외부에서 구축할 수 있다고 한다. 이를 "데이터 플레인"과 "컨트롤 플레인"으로 구성된 아키텍처로 구성한다고 한다.

아키텍쳐 그림을 보면 알수 있듯이 k8s와 뭐 유사하다면 유사하다고 할수 있듯이, mesh를 구성하는 실제 네트워크가 오가는 곳을 Data Plane 이라고 명칭하는 것 같다. Control Plane은 실제로 traffic을 오가거나 오가지 않게 하기 위한 그리고 네트워크를 오가는 과정에서 필요한 모든 Config를 관리하는 곳이라고 생각하면 되나 자세한 사항은 아래 내용에 더 있다.
이스티오 Istio : 서비스 매시의 오픈소스 구현체
이스티오를 사용하면 대부분의 경우 애플리케이션 코드를 수정하지 않고도 보안, 정책 관리, 관찰 가능성과 같은 어려운 문제를 해결할 수 있고, 신뢰성 있고 안전한 클라우드 네이티브 시스템을 구축할 수 있다.
이스티오의 데이터 플레인은 엔보이 프록시를 기반으로 한 서비스 프록시로 구성되며, 서비스 프록시는 애플리케이션 옆에 자리 잡고 있다.
서비스 프록시는 애플리케이션 간의 중개자 역할을 하며, 컨트롤 플레인이 전달한 설정에 따라 네트워킹 동작에 영향을 준다.
이스티오는 MSA 또는 서비스 지향 아키텍처 SOA 를 염두에 뒀지만, 그 아키텍처들에만 국한되지는 않는다.
현실에서는 대부분의 조직이 기존 애플리케이션과 플랫폼에 많은 투자를 하고 있다.
이들은 기존 애플리케이션을 중심으로 서비스 아키텍처를 구축할 가능성이 높으면, 이 부분이야말로 이스티오가 진가를 발휘하는 지점이다.
이스티오를 사용하면 기존 시스템을 바꾸지 않고도 애플리케이션 네트워킹 관심사를 구현할 수 있다.
Istio를 사용하면 애플리케이션 코드 단에서 네트워크 트래픽, 보안, 정책 등 어려운 일들을 애플리케이션에서 해결하기보다 Istio 라는 하나의 시스템을 두어서 해결할 수 있다.
Data Plane의 경우 "Envoy"를 기반으로 한 서비스 프록시로 구성되고 서비스 프록시는 애플리케이션 옆에 자리 잡고 있다고 한다. 이 말 뜻은 보통 Pod를 구성할 때 Pod 안에 애플리케이션 컨테이너와 Envoy Proxy 컨테이너를 동시에 두고 네트워킹을 하는 것으로 이해했고, 그런 사례라고 한다.
중요하게 이해해야할 점은 꼭 MSA나 SOA와 같은 아키텍처 뿐만 아니라 다른 아키텍처도 지원할 수 있으며 기존 애플리케이션을 중심으로 구축할 수 있어야 진가를 발휘한다는 점이다.
왜냐? Istio를 사용하면 기존 시스템(코드, 라이브러리 등)을 바꾸지 않고도 애플리케이션에 대한 네트워킹을 분리하여 처리할 수 있기 때문에
1.1 속도를 높이며 마주하는 문제들
HTTP GET +-------------+ --> [Database]
/customer/123 | Service B |
<------------------------> +-------------+
| |
| v
| JSON Response
|
+------------------+ HTTP PUT +-------------+
| ACMEmono | --------------------------------> | Service C |
| | /order/456 +-------------+
| | |
| | v
+------------------+ [Database]
|
| HTTP POST /foo
v
+-------------+
| Service A | --> [Database]
+-------------+한 서비스로부터 다른 여러 애플리케이션을 호출하는 경우 아래와 같은 문제가 있다.
- 서비스들의 요청 처리 시간이 매우 불규칙
- 배포를 자동화할 때 자동화된 테스트에서 잡히지 않은 버그가 발생
- 팀 별 다른 보안 정책 사용 (인증서, 개인 키), (토큰, 서명 검증), (방화벽 뒷단으로 별도 보안 없음)
그래서 해결점을 도출 해내야 한다.
- 장애가 격리 경계를 넘어 확산하는 것을 방지
- 환경 변화에 대응할 수 있는 애플리케이션/서비스 구축
- 부분적 장애 상태에서도 동작할 수 있는 시스템 구축
- 끊임없이 변화하고 발전하는 전체 시스템의 상태 파악
- 시스템의 런타임 동작을 제어할 수 없는 문제
- 공격 표면이 커짐에 따라 강력한 보안 구현하기
- 시스템 변경의 위험성 낮추기
- 시스템의 구성 요소를 누가(무엇이) /언제 사용할 수 있는지 정책 강제
여러 애플리케이션이 위 그림과 같이 API GW와 같은 구조를 띄고 있다면 외부로 통신하는 앞단에 위치하며 모든 서비스를 API GW를 통해서 통신해야 한다. 그 과정에서 요청 처리 시간이 불규칙하거나, A 서비스 요청 처리에 문제가 생긴 경우 특정 요청의 경우 B 서비스에도 문제가 생기는 문제, 배포 시 자동화된 테스트에서 잡히지 않은 버그가 발생, 팀 별로 인증서와 개인키 또는 토큰과 서명 및 검증 또는 방화벽 뒷단이므로 별도의 보안 정책 없는 등의 팀 별로 다른 보안 정책을 사용하기 때문에 위와 같은 문제들로 인한 효과들이 증폭되어 시스템 전체를 쓰러뜨릴 수 있다고 한다.
1.1.1 클라우드 인프라는 신뢰할 수 없다
- 클라우드에서는 인프라가 일시적이며 간혹 사용할 수 없다는 가정 아래 앱을 구축해야 한다. 이런 일시성은 아키텍처에서 미리 고려해야 한다.
- 예를 들어, 고객 선호도를 관리하는 추천 서비스가 고객 서비스를 호출한다고 해보자.
- 아래 그림에서 추천 서비스는 고객 서비스를 호출해 일부 고객 데이터를 업데이트 하는데, 메시지를 보낼 때 극심한 성능 저하를 경험한다.
- 이런 성능 저하는 어떤 영향을 미치는가?
- 의존하는 다운스트림이 느리면 추천 서비스가 실패해 연쇄 장애를 야기하는 등 혼란을 일으킬 수 있다.
- 이 시나리오는 여러 이유로 일어날 수 있다.
- 고객 서비스가 과부화돼 실행 속도가 느리다.
- 고객 서비스에 버그가 있다.
- 네트워크 방화벽이 트래픽을 느리게 한다.
- 네트워크가 혼잡해 트래픽이 느려지고 있다.
- 네트워크에 하드웨어 오류가 발생해 트래픽을 다시 라우팅하고 있다.
- 고객 서비스의 네트워크 카드 하드웨어에 오류가 발생했다.
- 문제는 이것이 고객 서비스의 장애인지 여부를 추천 서비스가 구분할 수 없다는 것이다.
- 다시 말하지만, 하드웨어 및 소프트웨어 구성 요소가 수백만 개에 달하는 클라우드 환경에서 이런 시나리오는 항상 일어난다.
+-------------+ ??? +-------------+
| Preference | -------------------------> | Customer |
+-------------+ +-------------+
|
|
+---> Uncertainty in the network (Latency, failure, retry, timeout...)
위의 예로는 추천 서비스 -> 고객 서비스로 예를 들었다. 클라우드 환경에서 위와 같은 서비스가 구성되어 있다고 했을 때 성능 저하를 완벽하게 고객 서비스의 장애 때문에 발생하는지 추천 서비스가 구분할 수 없다는 점이다.
만약 고객 서비스에 문제가 있거나 애플리케이션 문제가 아니더라도 하드웨어에 문제가 발생한다고 한들 "추천 서비스가 이를 명확히 이해하고 조치할 수 있다면 좋을텐데" 라는 생각이 든다.
1.1.2 서비스 상호작용을 복원력 있게 만들기
- 추천 서비스는 몇 가지를 시도할 수 있다.
- 이를테면 요청을 재시도할 수 있는데, 과부하 시나리오에서는 다운스트림에 문제를 더하기만 하는 꼴일 수 있다.
- 한편 요청을 재시도할 때는 이전 요청이 성공하지 못했다고 확신할 수 없다.
- 이럴 때는 일정 시간 후에 요청을 만료시키고 오류를 던질 수도 있다.
- 또한 다른 가용 영역에 위치할 수 있는 다른 고객 서비스 인스턴스에 재시도할 수도 있다.
- 만약 고객 서비스가 이런 문제를 장기간 겪을 경우, 추천 서비스는 냉각 기간 동안 고객 서비스 호출을 완전히 멈출 수도 있다.
- 이런 시나리오를 완화하고 예기치 않은 장애에 대해 애플리케이션 복원력을 높이는데 도움이 되는 몇 가지 패턴이 발전해왔다.
- 클라이언트 측 로드 밸런싱 Client-site load balancing
- 클라이언트에게 엔드포인트 목록을 제공하고 어떤 엔드포인트를 호출할지를 클라이언트가 결정하도록 한다.
- 서비스 디스커버리 Service discovery
- 특정 논리적 서비스의 주기적으로 갱신되는 정상 엔드포인트 목록을 찾는 매커니즘이다.
- 서킷 브레이커 Circuit breaking
- 오동작하는 것으로 보이는 서비스에 일정 시간 부하를 차단한다.
- 격벽 Bulkheading
- 서비스 호출 시 클라이언트 리소스 사용량을 명시적 임계값으로 제한한다 (커넥션, 스레드, 세션 등)
- 타임아웃 Timeouts
- 서비스 호출 시 요청, 소켓, 활성 liveness 등에 시간 제한을 적용한다.
- 재시도 Retries
- 실패한 요청을 재시도한다.
- 재시도 예산 Retry budgets
- 재시도에 제한을 적용. 즉, 일정 기간의 재시도 횟수를 제한하는 것 (예. 10초 동안 호출의 50%까지만 재시도 가능)
- 데드라인 Deadlines
- 요청에 응답 유효 기간을 지정한다. 데드라인을 벗어나면 요청 처리를 무시한다.
- 클라이언트 측 로드 밸런싱 Client-site load balancing
⇒ 이런 유형의 패턴을 종합하면 애플리케이션 네트워킹으로 생각할 수 있다.
이런 유형의 해결 방법들이 있는 것을 처음 알았다. 정확히는 여러가지 패턴으로 이미 개념이 정립되고 분류되어 있는 건지 몰랐다... 그리고 이렇게 패턴으로 분류 되어 있는 게 아주 좋다고 본다. 개중에는 K8s에서 이미 사용중인 패턴도 보인다. 이러한 패턴들을 이용해서 서비스끼리의 복원력을 올릴수 있다고 강력하게 공감한다.
1.1.3 일어나고 있는 일 실시간으로 이해하기
- 어떤 서비스가 서로 통신하고 있는지, 일반적인 서비스 부하가 어떤 형태인지, 예상하는 오동작 failure 수는 어는 정도인지, 서비스 오동작 시 어떤 일이 일어나는지, 서비스 상태가 어떤지 등 서비스 아키텍처를 아는 것은 대단히 중요하다.
- 새로운 코드나 설정을 배포해서 변화를 준다는 건 주요 메트릭에 부정적 영향을 미칠 수 있는 가능성을 도입하는 것이기도 하다.
- 메트릭, 로그, 트레이스로 시스템을 관찰하는 것은 서비스 아키텍처 운영에서 매우 중요한 부분이다.
1.2 이 과제를 애플리케이션 라이브러리로 해결해보기
들어가며
- 클라우드 환경에서 애플리케이션/서비스를 운영하는 방법을 최초로 알아낸 조직은 거대 인터넷 기업들이었고, 이 회사들은 모두가 사용해야 하는 일부 언어에 대한 라이브러리와 프레임워크를 구축하는 데 막대한 시간과 자원을 투자했고, 이는 클라우드 네이티브 아키텍처로 서비스를 운영할 때 생기는 문제를 해결하는 데 도움이 됐다.
- 구글은 stubby 같은 프레임워크를 구축했고,.. 등등 다음과 같은 클라우드 네이티브 문제를 처리한다.
- Hystrix—Circuit breaking and bulkheading
- Ribbon—Client-side load balancing
- Eureka—Service registration and discovery
- Zuul—Dynamic edge proxy
- 이 라이브러리는 자바 런타임을 대상으로 했기 때문에 자바 프로젝트에서만 사용할 수 있었다.
- 이러한 라이브러리를 사용하려면 해당 라이브러리에 대한 애플리케이션 의존성을 만들고, 클래스 경로를 가져온 다음, 애플리케이션 코드에서 사용해야 했다.
- NetflixOSS Hystrix 를 사용하는 다음 예제는 의존성 관리 시스템에 Hystrix 에 대한 의존성을 가져온다.
<dependency>
<groupId>com.netflix.hystrix</groupId>
<artifactId>hystrix-core</artifactId>
<version>x.y.z</version>
</dependency>Maven 의존성 설정 XML로 보인다. 이와 같이 특정 라이브러리로 관리해야 한다.
Hystrix 를 사용하려면 명령어를 기본 Hystrix 클래스인 HystrixCommand 로 래핑 wrapping 해야 한다.
public class CommandHelloWorld extends HystrixCommand<String> {
private final String name;
public CommandHelloWorld(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// a real example would do work like a network call here
return "Hello " + name + "!";
}
}- 만약 코드에 복원력을 구축할 책임이 각 애플리케이션에 있다면, 이런 문제에 대한 처리를 분산해 중앙 병목을 제거할 수 있다.
- 신뢰할 수 없는 클라우드 인프라에 대규모로 배포하는 경우, 이는 바람직한 시스템 특성이다.
위와 같은 경우 특정 라이브러리와 프레임워크를 구축해 문제를 해결하려고 했고, 라이브러리 종속성 문제를 해결할 수 없다. 지속적으로 라이브러리를 버전 관리와 같이 관리해야 하기 때문이다.
1.2.1 애플리케이션 별 라이브러리의 단점
- 새로운 도전 과제 1
- 모든 애플리케이션에서 예상되는 가정과 관련됨.
- 만약 아키텍처에 새 서비스를 도입하려 한다면, 예를 들어 Hystrix를 사용하려면 자바나 JVM 기반 기술을 사용해야만한다.
- 서킷 브레이커와 로드 밸런싱은 보통 함께 동작하므로, 두 복원력 라이브러리를 함께 사용해야 한다.
- 로드 밸런싱에 넷플릭스 Ribbon을 사용하고 싶다면, 서비스 엔드포인트 디스커버에 사용할 일종의 저장소가 필요한데, 이는 Eureka를 사용해야 한다는 의미일 수 있다.
- 이런 식으로 라이브러리를 사용하는 방법은, 시스템의 나머지 부분과 상호작용하는 프로토콜의 명확히 정의되지 않은 상태에서도 암묵적인 제약을 만들어 낸다.
- 새로운 도전 과제 2
- 서비스를 구현하려고 새로운 언어나 프레임워크를 도입하려고 할 때 발생한다.
- 사용자 대면 API를 구현하는 데 NodeJS가 적합하다고 판단했지만, 나머지 아키텍처는 자바와 NetflixOS를 사용하고 있다고 해보자.
- 당신은 복원력 패턴 구현용으로 다른 라이브러리 집합을 찾기로 할 수도 있다.
- 또는 relilient hystrixjs 와 같은 유사 패키지를 찾아볼 수 도 있다.
- 그러고는 도입하려는 언어를 알아보고, 입증하고, 개발 스택에 도입해야 한다.
- 이들 라이브러리 각각은 전제와 구현이 다를 것이다.
- 어떤 경우에는 각 프레임워크/언어 조합에 상응하는 유사 대체품을 찾지 못할 수도 있다.
- 결국 어떤 언어에서는 부분적으로 구현하게 돼 전반적으로 구현이 일괄적이지 않을 수 있는데, 이는 장애 시나리오에서 원인을 추론하기 어렵게 만들어 장애를 숨기거나 확산시키는 원인이 될 수 있다.
- 아래 그림은 서비스가 애플리케이션 네트워킹 관리 목적으로 동일한 라이브러리 집합을 구현하는 모습을 보여준다.
- 새로운 도전 과제 3
- 여러 프로그래밍 언어와 프레임워크에서 라이브러리를 소수로 유지하려면 많은 훈련이 필요하며 제대로 하기가 매우 어렵다.
- 핵심은 모두 구현이 일관되고 올바르다는 점을 보장하는 것이다.
- 하나의 차이만으로도 시스템의 예측 불가능성이 늘어난다.
- 동시에 여러 서비스에 업데이트를 수행하는 것도 벅찬 일이 될 수 있다.
- 클라우드 아키텍처에서는 애플리케이션 네트워킹을 분산하는 것이 낫지만, 그로 인해 늘어나는 시스템의 제약과 운영 부담은 대부분의 조직에서 감당하기 어려울 것이다.
- 설령 도전에 나선다고 해도 올바르게 수행하기는 더욱 어렵다.
- 애플리케이션을 임베디드 라이브러리로 유지 관리하고 운영하는 데 막대한 오버헤드 비용을 치르지 않고도 분산화의 이점을 누릴 수 있는 방법이 있다면 어떨까?
특정 라이브러리를 사용하게 되면 그 특정 라이브러리를 사용하게 됨으로써 오는 제약이 있다. 나머지 시스템을 구성하기 위해 다른 라이브러리를 사용하게 되는 의존적인 문제이다.
또한 특정 프레임워크 뿐만 아니라 서비스를 제공하는 환경이 여러 프레임워크로 구성되어 있다면, 해당 프레임워크에 동작하는 라이브러리나 대체품들을 찾지 못할수도 있다. 그렇게 되면 커스터마이징하게 개발해 부분적으로 구현해야 할 텐데 리소스가 들고, 원인 추론이 어려울 수 있다.
또한 이런 환경에서 라이브러리를 관리하고 시스템을 안정적으로 운영하는 데 많은 공수가 들게 된다. 이를 대부분의 조직에서는 감당하기 어려울 것이다.
1.3 이런 관심사(애플리케이션 네트워킹)를 인프라에 전가하기
들어가기
- 이런 기본적인 애플리케이션 네트워킹 문제는 특정 애플리케이션, 언어, 프레임워크만의 전유물이 아니다.
- 재시도, 타임아웃, 클라이언트 측 로드 밸런싱, 서킷 브레이킹 등이 애플리케이션 기능을 차별화하는 것도 아니다
- 이들이 서비스의 일부로 고려해야 하는 대단히 중요한 과제인 것은 맞지만, 사용하기로 한 모든 언어마다 구현하려고 막대한 시간과 자원을 투자하는 것은 시간 낭비다.

- 우리가 진정으로 원하는 점은 이런 과제를 구현해 애플리케이션이 자체적으로 처리해야 하는 부담을 덜어주면서도 기술에 구애받지 않는 방법이다.
위와 같은 아키텍처가 아까 말한 여러 프레임 워크로 구성되어 운영하기 어려운 환경이다.
1.3.1 애플케이션 인식 서비스 프록시
- 프록시를 사용하는 것은 이런 관심사를 인프라로 옮기는 방법 중 하나다.
- 프록시란 커넥션을 다룰 수 있고 적절한 백엔드로 리다이렉트할 수 있는 중간 인프라 구성 요소다.
- 필요한 것은 애플리케이션을 인식할 수 있고 서비스를 대신해 애플리케이션 네트워킹을 수행할 수 있는 프록시다.
- 그렇게 하려면 서비스 프록시는 커넥션과 패킷을 이해하는 전통적 인프라 프록시와 달리 메시지와 요청 같은 애플리케이션 구조를 이해해야 한다.
- 즉 7계층 프록시가 필요하다.
+-------------+ +-------------+ +-----------------------------+
| Service | ------------| Proxy |-------------> | Outbound Network Traffic |
+-------------+ +-------------+ +-----------------------------+
단순히 네트워킹을 하는 것이 아니라 애플리케이션에 대해 기민하게 통신해서 외부로 전달하는 과정이 필요하다고 이해가 된다.
1.3.2 엔보이 프록시 만나기
- 엔보이 Envoy 는 오픈소스 애플리케이션 수준 프록시이다.
- 리프트에서 SOA 인프라의 일부로 개발됐으며, 언어나 프레임워크에 명시적 의존성 없이도 재시도, 타임아웃, 서킷 브레이커, 클라이언트 측 로드 밸런싱, 서비스 디스커버리, 보안, 메트릭 수집 등의 네트워크 관심사를 구현할 수 있다.
- 아래 그림에서 보듯이 엔보이는 이 모든 것을 애플리케이션 프로세스 외부에서 구현한다.
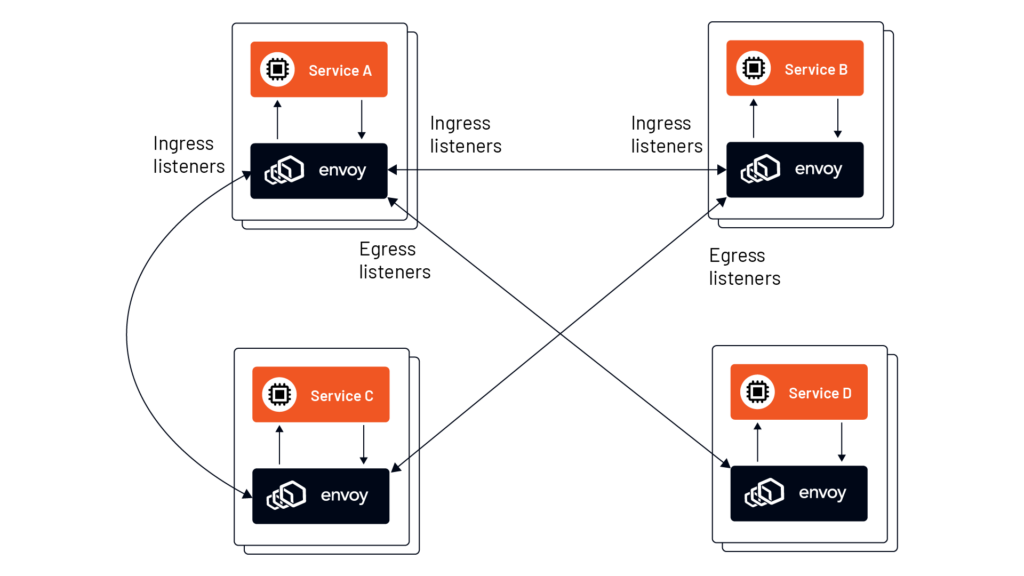
- 엔보이의 힘은 이런 애플리케이션 계층의 복원력 측면에서만 국한되지 않는다. 엔보이는 또한 초당 요청 수, 실패 횟수, 서킷 브레이커 이벤트와 같은 여려 애플리케이션 네트워킹 메트릭을 수집한다.
- 엔보이를 사용하면 서비스 간에 어떤 일이 일어나고 있는지 자동으로 알 수 있게 되는데, 바로 여기가 예상치 못한 복잡성을 많이 발견하는 되는 곳이다.
- 엔보이 프록시는 서비스 아키텍처에서 공통적인 서비스 간 신뢰성과 관찰 가능성 문제를 해결 할 수 있는 기반이여, 이 기반을 토대로 이런 문제를 애플리케이션에서 인프라로 이동시킬수 있다.
- 애플리케이션과 함께 서비스 프록시를 배포해 애플리케이션 외부에서 이런 기능들을 얻을 수 있지만, 세부적으로는 애플리케이션마다 다를 수 있다.
- 아래 그림은 이 모델에서 애플리케이션이 시스템의 다른 부분과 통신하는 방법을 보여주는데, 요청을 엔보이로 먼저 보내고 나서 엔보이가 업스트림으로의 통신을 처리한다.
엔보이 프록시는 아까 말한 기민한 네트워킹뿐만 아니라, 재시도, 타임아웃, 서킷 브레이커, 클라이언트 측 로드 밸런싱, 서비스 디스커버리, 보안, 메트릭 수집 을 특정 애플리케이션, 언어, 프레임워크에 의존성 없이도 제공할 수 있다.
- 또한 서비스 프록시는 분산 트레이싱 스팬 span을 수집해 특정 요청이 수행한 모든 단계를 연결할 수 있으며, 각 단계의 소요 시간을 확인하고 시스템의 잠재적인 병목 현상이나 버그를 찾아 낼 수 있다.
- 모든 애플리케이션이 자신의 프록시를 거쳐 외부 세계와 대화하고 애플리케이션으로 들어오는 모든 트래픽이 프록시를 거치면, 애플리케이션 코드를 한 줄도 바꾸지 않고 애플리케이션에 대한 중요한 기능을 얻을 수 있다.
- 이 프록시+애플리케이션 조합이 서비스 메시로 알려진 통신 버스의 토대가 된다.
- 엔보이 같은 서비스 프록시는 애플리케이션의 모든 인스턴스와 함께 단일 최소 단위 single atomic unit 로 배포할 수 있다.
- 예를 들어 쿠버네티스에서는 서비스 프록시와 애플리케이션 단일 파드로 함께 배포할 수 있다.
- 아래 그림은 메인 애플리케이션 인스턴스를 보완하기 위해 프록시를 배포하는 사이드카 배포 패턴을 그리고 있다.
이 부분이 정말 놀랜 부분이다. 서비스 프록시 자체에서 분산 트레이싱 스팬을 수집해서 분석하는 것은 보통 APM에서 해야할 일이라고 생각이 든다. 물론 APM 만큼 정확하게 어떤 api 호출이 문제가 발생했는지는 모를것 같으나, 네트워크의 문제인지 애플리케이션의 문제인지 파악할 수 있는 중점적인 힌트가 될 수 있을 것이라는 생각이 든다.
1.4 서비스 메시란 무엇인가?
들어가기
- 엔보이 같은 서비스 프록시는 클라우드 환경에서 동작하는 서비스 아키텍처에 중요한 기능을 추가하는 데 도움이 된다.
- 각 애플리케이션은 워크로드 목표를 감안해 프록시 동작 방식에 대해 자신만의 요구 사항이나 설정을 가질 수 있다.
- 애플리케이션과 서비스 수가 늘어남에 따라 많은 프록시를 설정하고 관리하는 것이 어려움 수 있다.
- 또한 각 애플리케이션 인스턴스에 프록시를 배치하면, 원래는 애플리케이션 스스로가 수행했어야 하는 흥미로운 고급 기능을 구축할 기회가 생긴다.
서비스 메시
서비스 메시란 애플리케이션 대신 프로세스 외부에서 투명하게 네트워크 트래픽을 처리하는 분산형 애플리케이션 인프라를 말한다.
- 데이터 플레인은 메시를 거쳐가는 트래픽을 설정하고 보호하고 제어하는 책임을 맡는다.
- 데이터 플레인의 동작은 컨트롤 플레인이 설정한다.
- 컨트롤 플레인은 메시의 두뇌로, 운영자가 네트워크 동작을 조작할 수 있도록 API를 노출한다.
- 데이터 플레인과 컨트롤 플레인이 모여 모든 클라우드 네트워크 아키텍처에 필요한 다음과 같은 중요 기능을 제공한다.
- 서비스 복원력
- 관찰 가능성 신호
- 트래픽 제어 기능
- 보안
- 정책 강제 Policy enforcement
서비스 메시는 데이터 플레인, 컨트롤 플레인으로 이루어져 있음
데이터 플레인 : 메시를 거쳐가는 트래픽을 설정하고 보호하고 제어하는 책임을 가짐.
컨트롤 플레인 : 데이터 플레인의 동작을 설정하고, 네트워크를 동작할 수 있도록 API 노출. 서비스 메시의 두뇌
-> 결과적으로 서비스 복원력, 관찰 가능성 신호, 트래픽 제어 기능, 보안, 정책 강제의 기능을 할 수 있다.

기능
- 서비스 메시는 재시도, 타임아웃, 서킷 브레이커 같은 기능을 구현해 서비스 통신이 장애에 복원력을 갖추게 만들 책임을 맡는다.
- 또한 서비스 디스커버리, 적응형 및 영역 인식 zone-aware 로드 밸런싱, 헬스 체크 같은 기능을 처리함으로써 변화하는 인프라 토폴로지를 처리할 수도 있다.
- 모든 트래픽이 메시를 통과하므로 운영자는 트래픽을 명시적으로 제어하고 지시할 수 있다.
- 트래픽이 메시를 통과하므로 요청 급증, 지연 시간, 처리량, 장애 등과 같은 메트릭을 추적함으로써 네트워크 동작에 대한 상세한 신호를 포착할 수 있다.
- 이 텔레메트리 telemetry 를 활용해 시스템에서 어떤 일이 일어나고 있는지 그려낼 수 있다.
- 마지막으로, 서비스 메시가 애플리케이션 간 네트워크 통신의 양쪽 끝을 제어하므로 상호 인증을 사용한 전송 계층 암호화 같은 강력한 보안을 적용할 수 있다.
- 구체적으로는 TLS 프로토콜을 사용할 수 있다.
서비스 메시 기능 정리
1. Retries, Timeouts, Circuit Breaker 같은 기능으로 복원력 제공
2. topology.kubernetes.io/region나 topology.kubernetes.io/zone를 이용해 zone-aware 로드 밸런싱 가능
3. VirtualService를 이용해 선언적인 트래픽 제어 및 관리 (예시 코드)
4. 트래픽에 대한 상세한 신호 포착, Traffic mirroring
5. 텔레메트리 활용
6. 상호 인증을 사용한 전송 계층 암호화 같은 강력한 보안. 구체적으로는 TLS 프로토콜. (mTLS)
정리
- 서비스 메시는 이 모든 기능을 애플리케이션 코드 변경이나 의존성 추가를 거의(혹은 전혀) 하지 않고도 서비스 운영자에게 제공한다.
- 일부 기능에서는 애플리케이션 코드와 약간의 협업이 필요하지만, 크고 복잡한 라이브러리 의존성을 피할 수 있다.
- 서비스 메시를 사용하면 애플리케이션을 구축하는 데 어떤 애플리케이션 프레임워크나 프로그래밍 언어를 사용했든지 상관없이 이런한 기능들이 일관되고 정확하게 구현되므로, 서비스 팀이 변화를 구현해 전달할 때 빠르고 안전하며 자신감 있게 움직일 수 있게 된다.
1.5 이스티오 서비스 메시 소개
들어가며
- 이스티오는 서비스 메시의 오픈소스 구현체이며 구글, IBM, 리프트가 주도했다.
- 이스티오는 서비스 아키텍처에 복원력과 관찰 가능성을 투명한 방식으로 추가하는 데 도움이 된다.
- 이스티오를 사용하면 애플리케이션은 자신이 서비스 메시의 일부임을 인지하지 않아도 된다.
- 애플리케이션이 외부 세계와 의사소통할 때는 항상 이스티오가 애플리케이션 대신 네트워킹을 처리하기 때문이다.
- 이스티오의 데이터 플레인은 엔보이 프록시를 사용하며, 서비스 프록시 인스턴스가 함께 배포되도록 애플리케이션을 구성하는 데 도움이 된다.
- 이스티오의 컨트롤 플에인은 최종 사용자/운영자용 API, 프록시용 설정 API, 보안 설정, 정책 선언 등을 제공하는 몇 가지 구성 요소로 이뤄져 있다.
- 이스티오는 본래 쿠버네티스에서 실행할 목적으로 구축됐지만, 배포 플랫폼에 구애받지 않는 관점으로 작성됐다.
- 즉, 쿠버네티스, 오픈시프트와 같은 배포 플랫폼은 물론, 가상머신 같은 기존 배포 환경에서도 이스티오 기반 서비스 메시를 사용할 수 있다.
- 각 애플리케이션 인스턴스 옆에 서비스 프록시가 있으면 애플리케이션은 더 이상 서킷 브레이커, 시간 초과, 재시도, 서비스 디스커버리, 로드 밸런싱 등을 위해 언어별 복원력 라이브러리가 필요하지 않다.
- 또한 서비스 프록시는 메트릭 수집, 분산 트레이싱, 접근 제어도 처리한다.
- 서비스 메시의 트래픽이 이스티오 서비스 프록시를 거쳐 흐르는 덕분에 이스티오는 각 애플리케이션에서 네트워킹 동작에 영향을 주고 지시할 수 있는 제어 지점을 가진다.
- 이를 통해 운영자는 트래픽 흐름을 제어하고 카나리 릴리즈, 다크 런치, 단계적 롤아웃, A/B 스타일 테스트와 같은 세밀한 릴리즈를 구현할 수 있다.
주요 특징
1. 외부와 통신하는 경우 이스티오가 애플리케이션 대신 네트워킹을 해줘서 애플리케이션 자신이 서비스 메시의 일부임을 인지하지 않아도 된다.
2. 엔보이 프록시를 사용하고, 서비스 프록시 인스턴스(Data Plane)가 함께 배포되도록 애플리케이션을 구성하는 데 도움이 된다.
3. Control Plane은 최종 사용자/운영자용 API, 프록시용 설정 API, 보안 설정, 정책 선언 등을 제공하는 몇 가지 구성 요소로 이루어져 있음
4. 쿠버네티스, 오픈시프트, Virtual Machine 등 배포 플랫폼애 구애받지 않고 이스티오 기반 서비스 메시 사용 가능
5. 서비스 프록시가 서킷 브레이커, Timeout, Retries, Service Discovery, Load Balancing을 해주기 때문에 언어별 복원력 라이브러리가 필요 없음.
6. 서비스 프록시는 메트릭 수집, 분산 트레이싱, 접근 제어도 처리함.
7. 서비스 메시 트래픽이 이스티오 서비스 프록시를 거쳐 각 애플리케이션에서 네트워킹을 지시할 수 있는 제어 지점을 가져, 운영자는 카나리 릴리즈, 다크 런치, 롤아웃, A/B 테스트 등 세밀한 배포 관리 가능.
예시 네트워크 흐름
- 트래픽은 이스티오 인그레스 게이트웨이를 통해 메시 외부의 클라이언트에서 클러스터로 들어온다.
- 트래픽이 쇼핑 카트 서비스로 이동한다. 트래픽은 먼저 해당 서비스 프록시를 통과한다.
- 서비스 프록시는 서비스에 타임아웃, 메트릭 수집, 보안 강제 등을 적용할 수 있다.
- 요청이 다양한 서비스를 거치므로, 이스티오의 서비스 프록시는 다양한 단계에서 요청을 가로채고 라우팅 결정을 내릴 수 있다.
- 이스티오의 컨트롤 플레인 istiod 는 라우팅, 보안, 텔레메트릭 수집, 복원력을 처리하는 이스티오 프록시를 설정하는 데 사용한다.
- 요청 메트릭은 주기적으로 다양한 수집 서비스로 전송된다. 분산 트레이싱 스팬은 트레이싱 저장소로 전송돼 시스템을 거치는 요청의 경로 및 지연 시간을 추후에 추적하는 용도로 사용할 수 있다.
1.5.1 서비스 메시와 엔터프라이즈 서비스 버스 ESB 의 관계
- 서비스 지향 아키텍처 SOA 시대의 엔터프라이즈 서비스 버스 ESB는 최소한 정신적으로는 서비스 메시와 유사하다.
- SOA 초기에 ESB가 본래 묘사됐던 방식을 살펴보면 다음과 같이 상당히 비슷한 표현을 볼 수 있다.
"The enterprise service bus (ESB) is a silent partner in the SOA logical architecture. Its presence in the architecture is transparent to the services of your SOA application."
- 위 설명에서 ESB를 ‘과묵한 파트너’로 가정하고 있는데, 이는 애플리케이션이 ESB를 알지 못함을 의미한다.
- 서비스 메시에서도 비슷한 동작을 기대한다. 서비스 메시는 애플리케이션에게 투명해야 한다.
- 또한 ESB는 ‘서비스 호출 작업을 단순하게 만드는 데 핵심적인 요소’라고 한다.
- ESB의 경우 프로토콜 변환, 메시지 변환, 콘텐츠 기반 라우팅을 포함한다.
- 서비스 메시는 EBS가 하던 모든 일을 맡지는 않는다.
- 서비스 메시는 재시도, 타임아웃, 서킷 브레이커로 서비스 복원력을 제공하고, 이에 더해 서비스 디스커버리와 로드 밸런싱 같은 서비스를 제공한다.
- 전반적으로 서비스 메시와 ESB에는 몇가지 중요한 차이점이 있다.
- ESB는 기업 내에서 서비스 통합을 관리하는 새로운 구조를 조직에 도입했는데, 이 구조는 결국 격리된 시스템, 즉 사일로 silo 가 됐다.
- ESB는 매우 중앙화된 배포/구현이었다.
- ESB는 애플리케이션 네트워킹과 서비스 중재 문제를 혼합했다.
- ESB는 복잡한 독점 벤더 소프트웨어를 기반으로 하는 경우가 많았다.
- 아래 그림은 ESB가 애플리케이션을 통합하는 방법을 보여준다.
- ESB는 중앙에 위치하고 애플리케이션 비즈니스 로직을 애플리케이션 라우팅,변환,중재와 결합했다.

ESB (enterprise service bus) 는 서비스 메시와 유사한 패턴. 서로 다른 애플리케이션 간의 실시간 데이터 교환을 지원하는 패턴.
서비스 메시와는 아래와 같은 차이점이 있다.
1. ESB는 기업 내 서비스 통합을 관리하는 새로운 구조를 조직에 도입 했는데 결국 Silo가 됐다.
2. 매우 중앙화된 배포/구현
3. 애플리케이션 네트워킹과 서비스 중재 문제를 혼합
4. 복잡한 독점 벤더 소프트웨어를 기반으로 함.
1.5.2 서비스 메시와 API 게이트웨이의 관계
- 이스티오와 서비스 메시 기술은 API 게이트웨이와도 몇 가지 유사점과 차이점을 공유한다.
- API 게이트웨이 인프라는 API 관리 제품군에서 조직의 공개 API에 외부에서 접근할 수 있는 엔드포인트를 제공하는 데 사용한다.
- API 게이트웨이의 역할은 크게 두 가지다.
- 첫 번째는 공개 API에 보안, 속도 제한, 할당량 관리, 메트릭 수집 기능을 제공하는 것이고,
- 두 번째는 API 계획 명세, 사용자 등록, 요금 청구와 기타 운영 문제를 포함하는 전반적 API 관리 솔루션에 공개 API를 연결하는 것이다.
- API 게이트웨이 아키텍처는 매우 다양하지만, 대부분 아키텍처의 경계에서 공개 API를 노출하는 데 사용됐다.
- 또한 보안, 정책, 메트릭 수집을 중앙화하기 위해 내부 API에도 사용돼 왔다.
- 그렇지만 API 게이트웨이는 트래픽이 흐르는 중앙집중 시스템을 만들기 때문에 ESB와 메시징 버스에서 설명했듯 병목 현상의 원인이 될 수 있다.
아래 그림은 내부 API에 API 게이트웨이를 사용할 때 서비스 간에 모든 내부 트래픽이 어떻게 API 게이트웨이를 거쳐가는지 보여준다.

- 그래프의 모든 서비스에서 홉 hop 이 두 번을 거치게 된다. 한번은 게이트웨이로 향하고, 한 번은 실제 서비스로 향하는 것이다.
- 이는 네트워크 오버헤드와 지연 시간 뿐 아니라 보안에도 영향을 미친다.
- 이런 다중 홉 아키텍처에서는 애플리케이션 관여 없이 API 게이트웨이가 단독으로 전송 매커니즘을 보호할 수 없다.
- 그리고 API 게이트웨이는 보통 서킷 브레이커나 격벽 같은 복원력 기능을 구현하지 않는다.
- 서비스 메시에서 프록시는 서비스와 함께 배치되므로 추가 홉을 거치지 않는다.
- 또한 서비스 메시는 탈중앙적이므로, 각 에플리케이션은 자신의 프록시를 자신의 워크로드에 맞게 설정할 수 있고 시끄러운 이웃 noisy neithbor 시나리오에 영향을 받지 않는다.
- 각 프록시는 짝 애플리케이션 인스턴스와 함께 있으므로, 애플리케이션이 알아차리거나 적극적으로 참여할 필요 없이 전송 매커니즘을 처음부터 끝까지 end-to-end 보호할 수 있다.
- 아래 그림은 서비스 프록시가 API 게이트웨이 기능을 구현하고 강제하는 장소가 되는 모습을 보여준다.

이스티오 같은 서비스 메시 기술이 계속 성숙하게 되면, API 관리가 서비스 메시 위에 구축되고 전문 API 게이트웨이 프록시가 필요하지 않게 될 것이다.
확실히 그림을 그리면서 느꼈는데 API 게이트웨이 그림보다 Istio를 사용한 그림이 훨~~~씬 그리기 쉬웠다. 그 만큼 이스티오의 네트워크 오버헤드나 지연이 적다는 의미로 느껴짐. 또한 여러 홉을 거치는 게 아니기 때문에 더 효율적으로 느낌
서비스 메시는 탈중앙적이라, 각 애플리케이션이 프록시를 워크로드에 맞게 설정하고, 시끄러운 이웃 시나리오에 영향을 받지 않는다.
프록시는 애플리케이션이 적극적으로 참여할 필요없이 end-to-end로 보호해준다.
1.5.3 마이크로서비스가 아닌 아키텍처에도 이스티오를 사용할 수 있는가?
- 이스티오의 힘이 빛을 발하는 것은 서비스 개수와 서비스 사이의 연결이 많고 네트워크가 신뢰할 수 없는 클라우드 인프라 위에 있으며 이런 구조가 여러 클러스터, 클라우드, 데이터센터에 걸쳐 확장되는 상황에서다.
- 게다가 이스티오가 애플리케이션 프로세스 외부에서 작동되므로, 기존 레거시 혹은 브라운필드 환경에서 배포해 메시에 통합할 수 있다.
- 이스티오에는 어떤 서비스와 통신할 수 있는지 강제하는 정책이 있는데, 이 기능은 온프레미스와 퍼블릭 클라우드를 모두 사용하는 하이브리드 클라우드 구조에서 대단히 유용해진다.
- 이스티오와 애플리케이션 둘 다 서킷 브레이커 같은 기능이 중복으로 구현했더라도, 더 제한적인 정책이 효과를 발휘해 모든 게 정상적으로 잘 작동할 것으므로 안심 할 수 있다.
근데 꼭 마이크로 서비스가 아닌데 이스티오를 사용해야하는 의문점도 있긴 하다. 클라우드 환경처럼 지속적으로 변경되는 애플리케이션 환경이 아니기 때문에 몇번 설정해놓으면 바뀔일이 없을 것 같다는 생각도 들고...
1.5.4 이스티오가 분산 아키텍처에 적합한 경우
- 구현에 사용할 기술은 당면한 문제와 필요한 기능을 고려해 선택해야 한다.
- 이스티오 같은 서비스 메시 기술은 강력한 인프라 기능이여 분산 아키텍처의 많은 영역에 영향을 미친다.
- 그렇지만 모든 문제에 적합한 것은 아니므로 모든 문제에 해결책으로 고려해서는 안된다.
- 아래 그림은 클라우드 아키텍처에서 애플리케이션 네트워킹 관심사를 이상적으로 분리하는 방법을 보여준다.
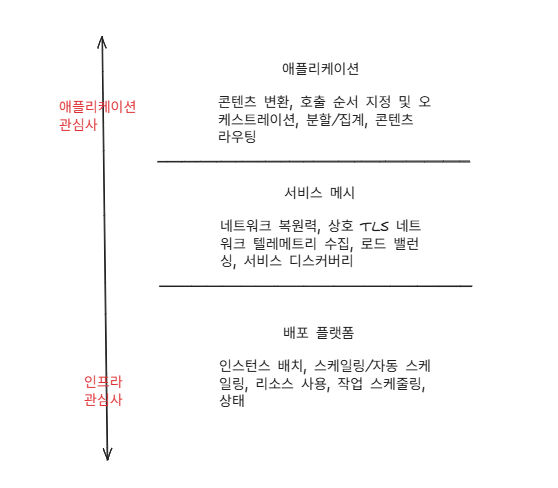
- 아키텍처의 하위 계층에는 배포 자동화 인프라가 있다.
- 이 인프라는 코드를 플랫폼에 배포하는 역할을 담당한다. 이스티오는 어떤 배포 자동화 도구를 사용해야 하는지를 규정하거나 침해하지 않는다.
- 상위 계층에는 애플리케이션 비즈니스 로직(코드)이 있다. 이 코드에는 비즈니스 도메인은 물론 어떤 서비스를 어떤 순서로 호출할지, 서비스 상호작용 응답을 어떻게 처리할지, 프로세스 실패 시 어떻게 처리할지 등이 포함된다.
- 이스티오는 어떤 비즈니스 로직도 구현하거나 대체하지 않는다. 또한 서비스 오케스트레이션, 비즈니스 페이로드 변환, 페이로드 강화, 분할 집계, 규칙 계산 등을 수행하지 않는다. 이런 기능은 애플리케이션 내부 라이브러리와 프레임워크에 맡기는 것이 가장 좋다.
- 이스티오는 배포 플랫폼과 애플리케이션 코드 사이의 연결 조직 역할을 한다.
- 복잡한 네트워킹 코드를 애플리케이션 외부로 꺼낼 수 있게 하는 것이다.
이스티오는 비즈니스 로직에 전혀 손대지 않고도 배포 플랫폼과 애플리케이션 코드 사이의 연결을 해주는 강력한 인프라 기능이다.
1.5.5 서비스 메시를 사용할 때의 단점은 무엇인가?
- 첫 번째로, 서비스 메시를 사용하면 요청 경로에 미들웨어, 특히 프록시가 추가된다.
- 이 프록시가 많은 이점을 주기도 하지만, 프록시에 익숙하지 않은 이들에게는 블랙박스가 돼 애플리케이션의 동작을 디버깅하기 어렵게 만들 수 있다.
- 엔보이 프록시는 아주 디버깅하기 쉽도록, 네트워크상에서 발생하고 있는 일을 많이 노출하게 특별히 설계됐다.
- 그렇지만 엔보이를 운영하는 데 익숙하지 않은 사람들에게는 아주 복잡해 보일 수 있고, 기존 디버깅 방식을 방해할 수 있다.
- 두 번째로, 테넌시 측면이다.
- 메시는 메시 내에서 실행되는 서비스 만큼 가치가 있다. 즉, 메시 내에 서비스가 많을수록 그 서비스들을 운영하는 데 메시의 가치가 높아진다.
- 그러나 물리적 메시 배포의 테넌트 및 격리 모델에 적절한 정책, 자동화, 그리고 사전 고려 없이는 메시를 잘못 구성하면 많은 서비스에 영향을 미칠 수 있는 상황에 처할 수 있습니다. → 학습 필요. 잘 알고 설정 필요
- 마지막으로, 서비스 메시는 요청 경로에 위치하기 때문에 서비스 및 애플리케이션 아키텍처의 매우 중요한 요소가 된다.
- 서비스 메시는 보안, 관찰 가능성 및 라우팅 제어 자세를 개선할 수 있는 많은 기회를 제공할 수 있습니다.
- 단점은 메쉬가 또 다른 레이어와 또 다른 복잡성의 기회를 제공한다는 점입니다.
- 운영상 이슈(R&R) : 서비스 메시를 어떻게 설정하고 운영해야 하는지, 기존 조직의 절차와 거버넌스에는 어떻게 통합해야 하는지, 또한 팀 간에는 어떻게 통합해야 하는지 이해하기가 어려울 수 있다.
- 일반적으로 서비스 메시가 가져다주는 이점이 크지만, 그에 따른 트레이드오프가 없지 않다.
- 다른 도구나 플랫폼과 마찬가지로 사용자는 자신의 맥락 및 제약 조건에 비춰 트레이드오프를 평가하고, 서비스 메시가 자신의 상황에 적합한지 판단해야 한다.
- 만약 적합하다면 메시를 성공적으로 도입하기 위한 계획를 세워야 한다.
서비스 메시 단점 정리
1. 요청 경로에 프록시가 추가되어, 프록시에 익숙치 않은 사람들에게는 애플리케이션의 동작을 디버깅하기 어렵게 만들 수 있다. 그런게 엔보이 프록시는 네트워크 상에서 발생하고 있는 일을 많이 노출하게 설계되어 디버깅하기 쉬움!
2. 메시는 메시 내에 서비스가 많을 수록 서비스들을 운영하는 데 가치가 높아짐. 사전 고려 없이 메시를 잘못 구성하면 많은 서비스에 영향을 미칠 수 있는 상황에 처할 수 있다.
3. 메시는 보안, 관찰 가능성 및 라우팅 제어 자세를 개선할 수 있음. 그러나 또 다른 레이어와 또 다른 복잡성을 제공한다. 예를 들어 서비스 메시의 설정 및 운영, 조직의 절차와 거버넌스는 어떻게 통합하는지, 팀 간에 어떻게 통합하는지 이해하기 어려울 수 있음.
2장 이스티오 첫걸음
먼저 로컬 PC에 k8s 환경을 구동하기 위해 kind 를 설치하고 해당 환경 안에서 여러 가지 실습을 해 보았다.
나는 Window를 사용하고 있었기에 미리 WSL2로 Ubuntu를 설치해 놓았다.

kind 설치 과정
물론 kind도 미리 설치된 환경이라 설치하는 과정을 모두 보여주지는 못하지만 가시다 님이 공유해주신 아주 좋은 커맨드들이 있기 때문에 무리없이 설치가 될 것이다.
# 클러스터 배포 전 확인
docker ps
mkdir ~/aews-labs
cd ~/aews-labs
# Create a cluster with kind : 1.29.14 , 1.30.10 , 1.31.6 , 1.32.2
kind create cluster --name myk8s --image kindest/node:v1.32.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
bind-address: "0.0.0.0"
etcd:
local:
extraArgs:
listen-metrics-urls: "http://0.0.0.0:2381"
scheduler:
extraArgs:
bind-address: "0.0.0.0"
- |
kind: KubeProxyConfiguration
metricsBindAddress: "0.0.0.0"
EOF
# 확인
kind get nodes --name myk8s
kubens default
# kind 는 별도 도커 네트워크 생성 후 사용 : 기본값 172.18.0.0/16
docker network ls
docker inspect kind | jq
# k8s api 주소 확인 : 어떻게 로컬에서 접속이 되는 걸까?
kubectl cluster-info
# 노드 정보 확인 : CRI 는 containerd 사용
kubectl get node -o wide
# 파드 정보 확인 : CNI 는 kindnet 사용
kubectl get pod -A -o wide
# 네임스페이스 확인 >> 도커 컨테이너에서 배운 네임스페이스와 다릅니다!
kubectl get namespaces
# 컨트롤플레인노드(컨테이너) 확인 : 도커 컨테이너 이름은 myk8s-control-plane
docker ps
docker images
docker exec -it myk8s-control-plane ss -tnlp
# 디버그용 내용 출력에 ~/.kube/config 권한 인증 로드
kubectl get pod -v6
# kube config 파일 확인 : "server: https://127.0.0.1:YYYYY" 127.0.0.1:Port로 접속 가능을 확인!
cat ~/.kube/config
ls -l ~/.kube/config
추가적으로 kube-ops-view나 metrics-server 도 설치하는 것이 좋다.
# (옵션) kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=NodePort,service.main.ports.http.nodePort=30005 --set env.TZ="Asia/Seoul" --namespace kube-system
kubectl get deploy,pod,svc,ep -n kube-system -l app.kubernetes.io/instance=kube-ops-view
## kube-ops-view 접속 URL 확인
open "http://localhost:30005/#scale=1.5"
open "http://localhost:30005/#scale=1.3"
# (옵션) metrics-server
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm install metrics-server metrics-server/metrics-server --set 'args[0]=--kubelet-insecure-tls' -n kube-system
kubectl get all -n kube-system -l app.kubernetes.io/instance=metrics-server중간에 `open "http://localhost:30005/#scale=1.5"` 명령어가 있는데 WSL2 에서는 명령어를 사용할 수가 없으니 chrome 브라우저와 같은 웹 브라우저에 해당 url 을 입력하면 바로 들어가지니 웹 브라우저로 들어가는 것을 추천한다.
# 클러스터 삭제
kind delete cluster --name myk8s
docker ps
cat ~/.kube/config
아래는 istio를 실습하기 위해 구성한 클러스터이다.
#
git clone https://github.com/AcornPublishing/istio-in-action
cd istio-in-action/book-source-code-master
pwd # 각자 자신의 pwd 경로
code .
#
kind create cluster --name myk8s --image kindest/node:v1.23.17 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000 # Sample Application (istio-ingrssgateway)
hostPort: 30000
- containerPort: 30001 # Prometheus
hostPort: 30001
- containerPort: 30002 # Grafana
hostPort: 30002
- containerPort: 30003 # Kiali
hostPort: 30003
- containerPort: 30004 # Tracing
hostPort: 30004
- containerPort: 30005 # kube-ops-view
hostPort: 30005
extraMounts:
- hostPath: /root/istio_gasida/istio-in-action/book-source-code-master # 각자 자신의 pwd 경로로 설정
containerPath: /istiobook
networking:
podSubnet: 10.10.0.0/16
serviceSubnet: 10.200.1.0/24
EOF
# 설치 확인
docker ps
# 노드에 기본 툴 설치
docker exec -it myk8s-control-plane sh -c 'apt update && apt install tree psmisc lsof wget bridge-utils net-tools dnsutils tcpdump ngrep iputils-ping git vim -y'아까와 다른 점은 extraMounts: 항목이 있는데, 이는 클러스터 노드 환경에서 실습을 하기 위해 미리 설치해 놓은 코드와 file들을 마운트하는 것이다. 꼭 유의해서 본인의 pwd 경로로 설치해야 한다.

나 같은 경우 미리 istio-in-action을 clone 해놓았다. 해당하는 path를 유의해서 변경하길 바란다!


위와 같이 명령어를 이용해서 cluster를 확인할수도 있다. 노드 또한 kubectl 명령어를 이용해서 확인 가능하다.
옵션으로 prometheus, grafana 등의 툴도 설치하는 스크립트.
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
service:
type: NodePort
nodePort: 30001
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
service:
type: NodePort
nodePort: 30002
defaultRules:
create: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
alertmanager:
enabled: false
EOT
cat monitor-values.yaml
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
# 각각 웹 접속 실행
## Windows(WSL2) 사용자는 아래 주소를 자신의 웹 브라우저에서 기입 후 직접 접속, 이후에도 동일.
open http://127.0.0.1:30001 # macOS
open http://127.0.0.1:30002 # macOS
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress,pvc -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring
# 삭제
helm uninstall -n monitoring kube-prometheus-stack
[2.2 Istio control plane 알아보기]
- 들어가며
- Istio control plane 제공 기능
- 운영자가 원하는 라우팅/회복력 routing/resilience 동작을 지정할 수 있는 API
- 데이터 플레인 설정을 위한 API
- 데이터 플레인에 대한 서비스 검색 추상화 service discovery abstraction
- 사용자 정책 specifying usage policies 지정 API
- 인증서 발급 및 순환 Certificate issuance and rotation
- 워크로드 ID 할당 Workload identity assignment
- 통합 원격 측정 컬렉션 Unified telemetry collection
- 서비스 프록시 사이드카 주입 Service-proxy sidecar injection
- 네트워크 경계 지정 및 접근 방법 Specification of network boundaries and how to access them
- 위 기능 대부분은 istiod 라는 단일 컨트롤 플레인 구성 요소에 구현돼 있다.
- Istio control plane 제공 기능
2.2.1 istiod
- 이스티오의 컨트롤 플레인 역할은 istiod로 구현된다.
- 이스티오 파일럿 istio pilot 이라고도 하는 istiod 는 사용자나 운영자가 지정한 Higher-Level 이스티오 설정을 받아 이르 각 데이터 플레인 서비스 프록시에 맞는 프록시 전용 설정으로 변환하는 역할을 한다.
- 이스티오는 ‘선언형 설정’을 해석해 서비스 프록시 전용 설정으로 적용된다.
- 이스티오는 서비스 프록시로 엔보이를 사용하므로 이 설정들은 엔보이 설정으로 변환된다.
- 예를 들어 아래 처럼 ‘선언형 설정’과 변환된 ‘엔보이 설정’
# istip api 선언형 설정
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: catalog
spec:
hosts:
- catalog
http:
- match:
- headers:
x-dark-launch:
exact: "v2"
route:
- destination:
host: catalog
subset: version-v2
- route:
- destination:
host: catalog
subset: version-v1# 변환된 ‘엔보이 설정’
"domains": [
"catalog.prod.svc.cluster.local"
],
"name": "catalog.prod.svc.cluster.local:80",
"routes": [
{
"match": {
"headers": [
{
"name": "x-dark-launch",
"value": "v2"
}
],
"prefix": "/"
},
"route": {
"cluster": "outbound|80|v2|catalog.prod.svc.cluster.local",
"use_websocket": false
}
},
{
"match": {
"prefix": "/"
},
"route": {
"cluster":
"outbound|80|v1|catalog.prod.svc.cluster.local",
"use_websocket": false
}
}
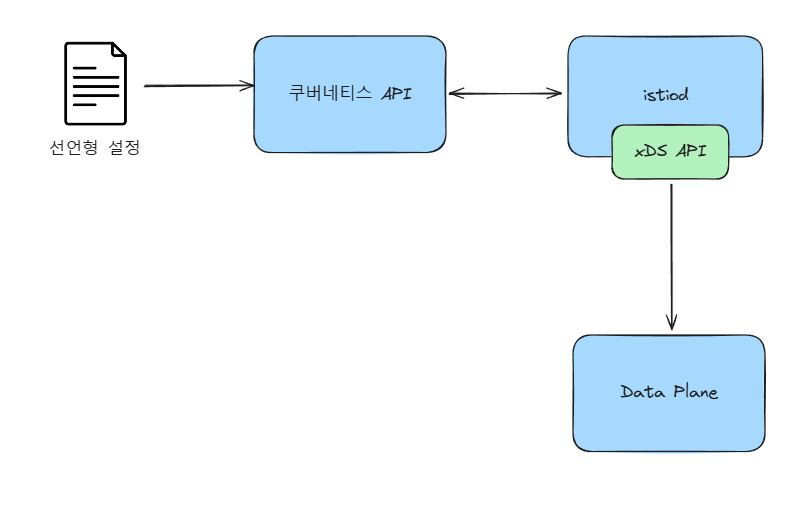
]- istiod가 노출하는 이 데이터 플레인 API는 엔보이의 디스커버리 API를 구현한다.
- 서비스 디스커버리용(LDS, Listener Discovery Service), 엔드포인트용(EDS, Endpoint DS), 라우팅 큐칙용(RDS, Route DS) 등과 같은 이런 디스커버리 API를 xDS API라고 부른다.
- 이 API들이 있어서 데이터 플레인이 설정 방식을 분리할 수 있으며, 중지/재시작 없이 Envoy 에 동적으로 설정을 적용 할 수 있다.
- 이스티오의 핵심 기능 중 하나는 각 워크로드 인스턴스에 ID를 할당하고 서비스 간 네트워크 전송을 암호화하는 것이다.
- 이 기능은 서비스 메시가 요청 경로 양 끝단 모두에 위치한 덕분에 가능하다. 이때 이스티오는 트래픽 암호화에 X.509 인증서를 사용한다.
- 워크로드 ID는 SPIFFE 사양에 따라 이 인증서에 내장된다. https://spiffe.io/
- 덕분에 이스티오에서는 애플리케이션이 인증서, 공개/비밀키 등을 인지할 필요 없이 강력한 상호 인증(mTLS)을 사용할 수 있다.
- 이런 보안을 가능케 하는 인증서의 검증, 서명, 전달 및 로테이션은 istiod가 다룬다.

istio의 컨트롤 플레인 역할은 istiod로 구현됨.
istiod는 사용자나 운영자가 지정한 Higher-Level 이스티오 설정을 받아 각 데이터 플레인 서비스 프록시에 맞는 프록시 전용 설정으로 변환.
2.2.2 인그레스 및 이그레스 게이트웨이 Ingress and egress gateway
- 이스티오가 동작하는 K8S 클러스터 내부망에 들어오거나 빠져나갈때 동작하는 구성요소인 Ingress/Egress Gateway.
- 이 두 구성요소는 이스티오 설정을 이해할 수 있는 엔보이 프록시이다.
- 애플리케이션과 함께 작동하는 이스티오 서비스 프록시와 매우 유사하게 설정된다.
- 차이점은 어떤 애플리케이션 워크로드에도 독립적이며 트래픽이 클러스터로 드나드는 것을 허용하는 역할뿐이라는 점이다.
istio 1.17.8 설치
아래는 Istio를 설치하는 스크립트이다. 중간중간 확인하는 명령어가 있어 한줄 한줄 확인하며 설치하길 바란다!
# myk8s-control-plane 진입 후 설치 진행
docker exec -it myk8s-control-plane bash
-----------------------------------
# 코드 파일들 마운트 확인
tree /istiobook/ -L 1
# istioctl 설치
export ISTIOV=1.17.8
echo 'export ISTIOV=1.17.8' >> /root/.bashrc
curl -s -L https://istio.io/downloadIstio | ISTIO_VERSION=$ISTIOV sh -
tree istio-$ISTIOV -L 2 # sample yaml 포함
cp istio-$ISTIOV/bin/istioctl /usr/local/bin/istioctl
istioctl version --remote=false
# default 프로파일 컨트롤 플레인 배포
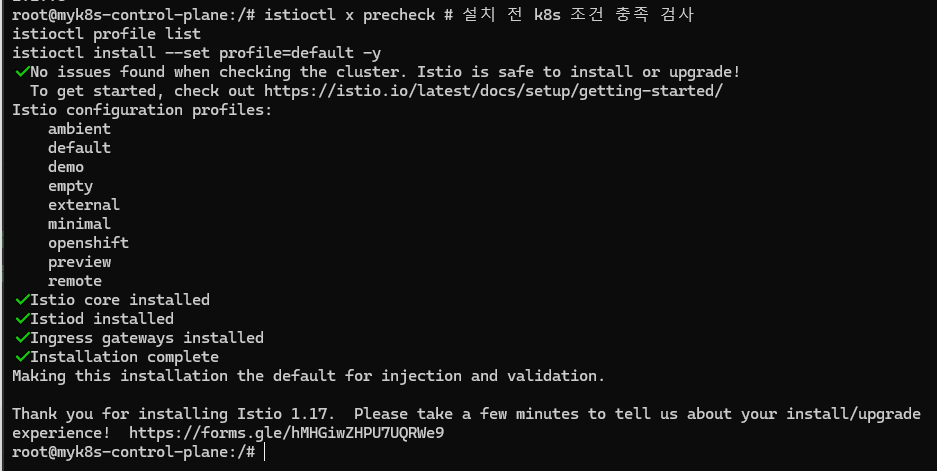
istioctl x precheck # 설치 전 k8s 조건 충족 검사
istioctl profile list
istioctl install --set profile=default -y
✔ Istio core installed
✔ Istiod installed
✔ Ingress gateways installed
✔ Installation complete
# 설치 확인 : istiod, istio-ingressgateway, crd 등
kubectl get all,svc,ep,sa,cm,secret,pdb -n istio-system
...
NAME READY STATUS RESTARTS AGE
istio-ingressgateway-58888b4f9b-gv7r9 1/1 Running 0 2m43s
istiod-78c465d86b-tsd8l 1/1 Running 0 3m
...
kubectl get crd | grep istio.io | sort
istioctl verify-install # 설치 확인
# 보조 도구 설치
kubectl apply -f istio-$ISTIOV/samples/addons
#
kubectl get pod -n istio-system
NAME READY STATUS RESTARTS AGE
grafana-67f5ccd9d7-cgkn4 1/1 Running 0 86s
istio-ingressgateway-58888b4f9b-7t5zj 1/1 Running 0 116s
istiod-78c465d86b-pvqv6 1/1 Running 0 2m14s
jaeger-78cb4f7d4b-d8b88 1/1 Running 0 86s
kiali-c946fb5bc-4njln 1/1 Running 0 86s
prometheus-7cc96d969f-6ft4s 2/2 Running 0 86s
# 빠져나오기
exit
-----------------------------------
#
kubectl get cm -n istio-system istio -o yaml
kubectl get cm -n istio-system istio -o yaml | kubectl neat

중간에 `root@myk8s-control-plane:/#` 쉘이 이렇게 표시되는 부분은 docker exec 명령어를 이용해서 노드로 직접 접속한 부분이니 유의해서 명령어를 입력하길 바란다.


위와 같이 istioctl 을 이용해서 설치를 확인할수도 있고, kubectl get 명령어를 이용해서도 istio가 성공적으로 설치되었음을 확인할 수 있다.
위 설치 스크립트에서 `kubectl get cm -n istio-system istio -o yaml | kubectl neat` 명령어가 있는데 kubectl neat는 krew로 설치 가능한 plugin 이라고 한다. kubectl-neat 나는 krew를 설치하다가 잘 안되어서 말았다... (시간이 되면 설치 과정도 담아 보겠다. 다음 진행을 위해서 넘어감!)
[2.3 Deploying your first application in the service mesh] 서비스 메시에 첫 애플리케이션 배포
istio를 설치하고 나면 아래와 같은 구성으로 이루어진다고 한다.
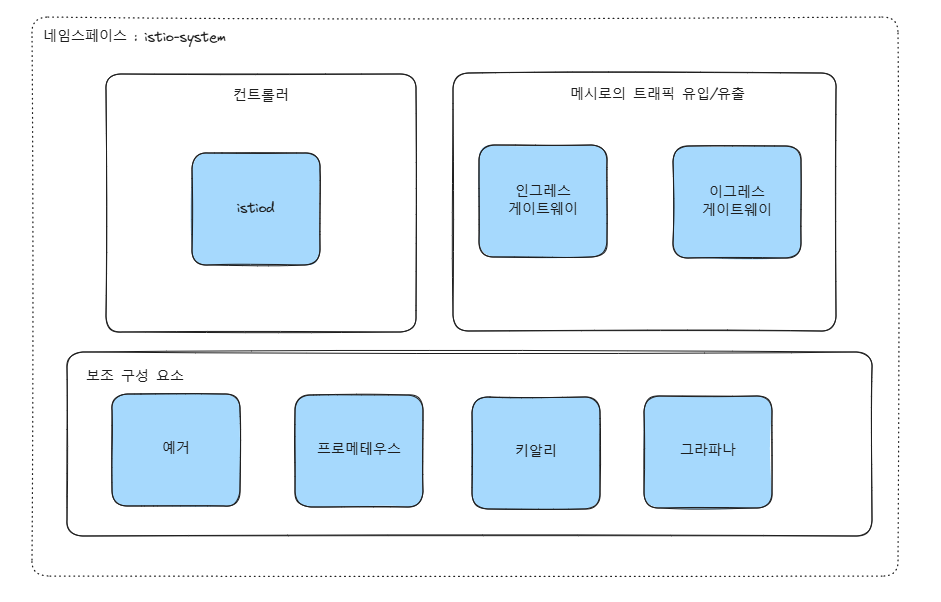
이 중 istiod(컨트롤 플레인)는 여러 기능이 구현돼 있다.
istiod는 idtio Pilot 이라고도 하며, 사용자나 운영자가 지정한 고수준 이스티오 설정을 받아 각 데이터 플레인 서비스 프록시에 맞는 프록시 전용 설정으로 변환하는 역할을 한다.
#
kubectl create ns istioinaction
# 방법1 : yaml에 sidecar 설정을 추가
cat services/catalog/kubernetes/catalog.yaml
docker exec -it myk8s-control-plane istioctl kube-inject -f /istiobook/services/catalog/kubernetes/catalog.yaml
...
- args:
- proxy
- sidecar
- --domain
- $(POD_NAMESPACE).svc.cluster.local
- --proxyLogLevel=warning
- --proxyComponentLogLevel=misc:error
- --log_output_level=default:info
- --concurrency
- "2"
env:
- name: JWT_POLICY
value: third-party-jwt
- name: PILOT_CERT_PROVIDER
value: istiod
- name: CA_ADDR
value: istiod.istio-system.svc:15012
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
...
image: docker.io/istio/proxyv2:1.13.0
name: istio-proxy
# 방법2 : namespace에 레이블을 추가하면 istiod (오퍼레이터)가 해당 namepsace의 pod spec에 자동으로 sidecar 설정을 주입
kubectl label namespace istioinaction istio-injection=enabled
kubectl get ns --show-labels
#
kubectl get mutatingwebhookconfiguration
NAME WEBHOOKS AGE
istio-revision-tag-default 4 9m24s # 특정 revision의 사이드카 주입 설정 관리
istio-sidecar-injector 4 9m45s # Istio는 각 애플리케이션 Pod에 Envoy 사이드카 프록시를 자동으로 주입
## 네임스페이스나 Pod에 istio-injection=enabled 라벨이 있어야 작동
kubectl get mutatingwebhookconfiguration istio-sidecar-injector -o yaml
#
kubectl get cm -n istio-system istio-sidecar-injector -o yaml | kubectl neat
위는 kubernetes 리소스 파일에 Envoy 사이드카 컨테이너를 주입해주는 과정이다. 방법은 두 가지 있다. `docker exec -it myk8s-control-plane istioctl kube-inject -f /istiobook/services/catalog/kubernetes/catalog.yaml` 명령어와 같이 수동으로 config를 주입해주어 사이드카를 주입해주는 것과 namespace에 istio-injection=enabled 레이블을 추가해 사이드카를 주입할 수 있다.


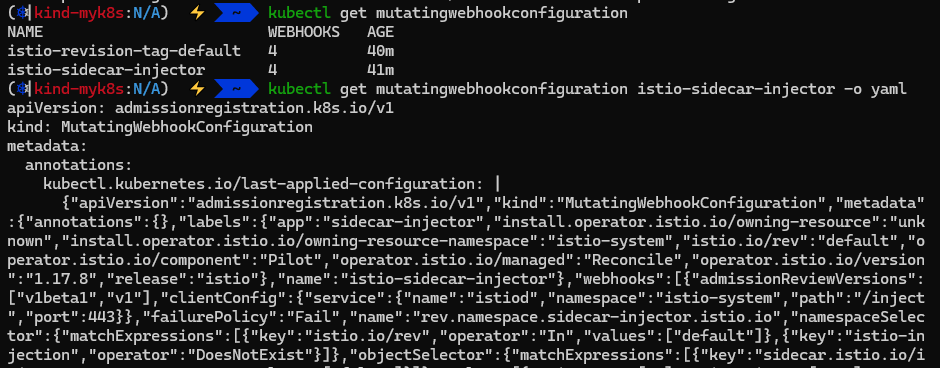
위는 pod에 자동으로 Envoy 사이드카 주입을 도와주는 mutatingwebhookconfiguration이 설정되어 있는 모습이다.
아래는 실제 애플리케이션을 배포해 확인하는 과정이다.
# source file 위치로 이동
cd /root/istio_gasida/istio-in-action/book-source-code-master
#
cat services/catalog/kubernetes/catalog.yaml
kubectl apply -f services/catalog/kubernetes/catalog.yaml -n istioinaction
cat services/webapp/kubernetes/webapp.yaml
kubectl apply -f services/webapp/kubernetes/webapp.yaml -n istioinaction
#
kubectl get pod -n istioinaction
NAME READY STATUS RESTARTS AGE
catalog-6cf4b97d-jx8xw 2/2 Running 0 29s
webapp-7685bcb84-zlxmv 2/2 Running 0 29s
# 접속 테스트용 netshoot 파드 생성
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot
spec:
containers:
- name: netshoot
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
# catalog 접속 확인
kubectl exec -it netshoot -- curl -s http://catalog.istioinaction/items/1 | jq
{
"id": 1,
"color": "amber",
"department": "Eyewear",
"name": "Elinor Glasses",
"price": "282.00"
}
# webapp 접속 확인
kubectl exec -it netshoot -- curl -s http://webapp.istioinaction/api/catalog/items/1 | jq
{
"id": 1,
"color": "amber",
"department": "Eyewear",
"name": "Elinor Glasses",
"price": "282.00"
}위 코드도 본인 path에 맞게 변경하길 바란다.




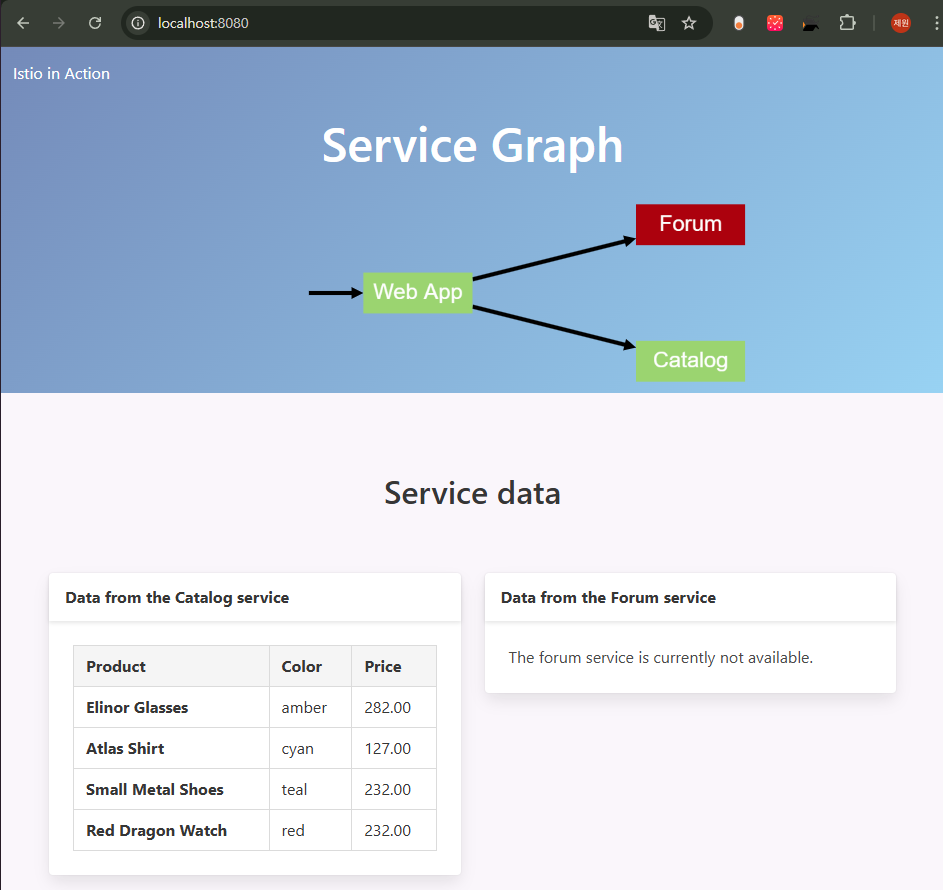
이렇게 실제 애플리케이션이 설치 되었다. 이를 이용해 트래픽을 어떻게 확인하고 제어하는지 알아보자
[2.4 Exploring the power of Istio with resilience, observability, and traffic control] 복원력, 관찰가능성, 트래픽 제어

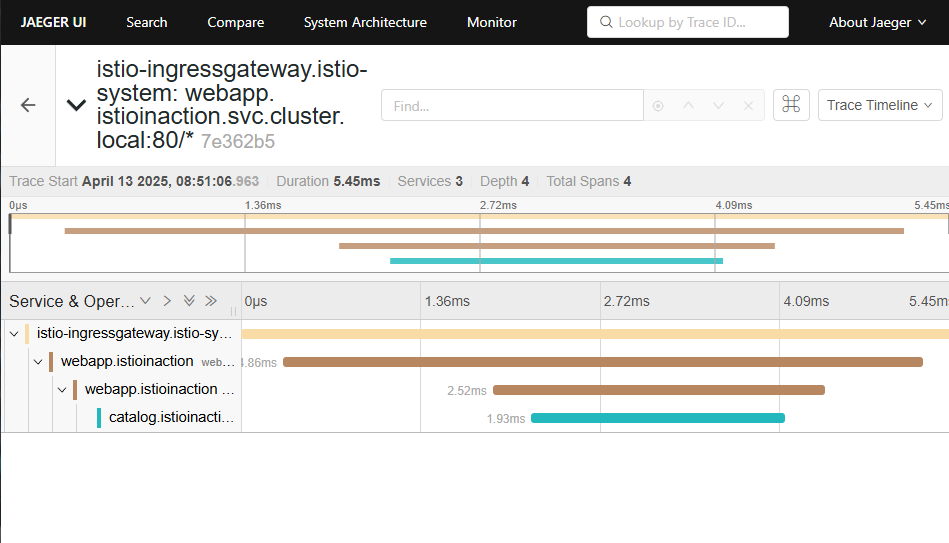
- 두 개의 애플리키에션이 있을 때 이스티오 프록시가 애플리케이션 호출 경로 양쪽에 위치하는 덕분에 이스티오는 애플리케이션 사이의 모든 일에 텔레메트리를 수집하고 통찰력을 향상시킬 수 있다.
- 이스티오의 서비스 프록시는 사이드 카로 배포되므로, 애플리케이션 프로세스의 외부에서 통찰력이 나온다.
- 대부분의 애플리케이션은 이런 관찰력을 얻기 위해 라이브러리나 프레임워크에 특정 구현을 하게 되는데 이럴 필요가 없다.
- 이스티오가 생성하는 텔레메트리는 2가지 주요 범주가 있다.
- 초당 요청 수, 실패 횟수, 지연 시간 백분위수와 같은 주요 메트릭이다. 이런 값을 알면 시슽메에서 문제가 시작되는 지점에 대한 훌룡한 통찰력을 얻을 수 있다.
- 두 번째로 분산 트레이싱 지원이다. 이스티오는 애플리케이션들이 신경 쓰지 않아도 분산 트레이싱 백엔드로 스팬을 보낼 수 있다. 이렇게 하면 특정 서비스 상호작용 중에 어떤 일이 일어났는지, 어디에서 지연이 발생했는지를 확인하고 전반적인 호출 지연에 대한 정보를 얻을 수 있다.
# istioctl proxy-status : 단축어 ps
docker exec -it myk8s-control-plane istioctl proxy-status
docker exec -it myk8s-control-plane istioctl ps
#
cat ch2/ingress-gateway.yaml
cat <<EOF | kubectl -n istioinaction apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: outfitters-gateway
namespace: istioinaction
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: webapp-virtualservice
namespace: istioinaction
spec:
hosts:
- "*"
gateways:
- outfitters-gateway
http:
- route:
- destination:
host: webapp
port:
number: 80
EOF
#
kubectl get gw,vs -n istioinaction
NAME AGE
gateway.networking.istio.io/outfitters-gateway 126m
NAME GATEWAYS HOSTS AGE
virtualservice.networking.istio.io/webapp-virtualservice ["outfitters-gateway"] ["*"] 126m
# istioctl proxy-status : 단축어 ps
docker exec -it myk8s-control-plane istioctl proxy-status
NAME
ingress-gateway 적용

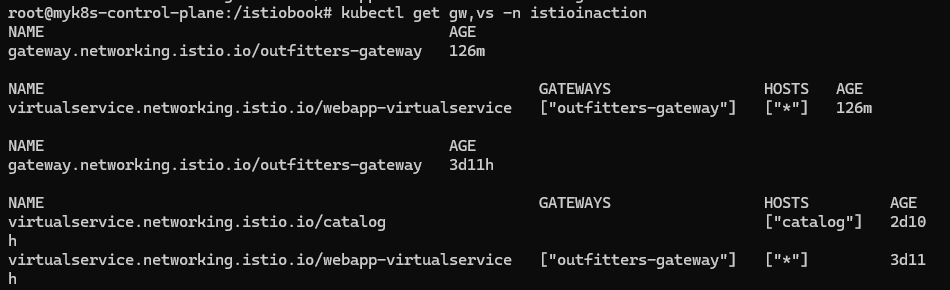
docker exec -it myk8s-control-plane istioctl proxy-config routes deploy/istio-ingressgateway.istio-system
NAME DOMAINS MATCH VIRTUAL SERVICE
http.8080 * /* webapp-virtualservice.istioinaction
* /stats/prometheus*
* /healthz/ready*
# istio-ingressgateway 서비스 NodePort 변경 및 nodeport 30000로 지정 변경
kubectl get svc,ep -n istio-system istio-ingressgateway
kubectl patch svc -n istio-system istio-ingressgateway -p '{"spec": {"type": "NodePort", "ports": [{"port": 80, "targetPort": 8080, "nodePort": 30000}]}}'
kubectl get svc -n istio-system istio-ingressgateway
# istio-ingressgateway 서비스 externalTrafficPolicy 설정 : ClientIP 수집 확인
kubectl patch svc -n istio-system istio-ingressgateway -p '{"spec":{"externalTrafficPolicy": "Local"}}'
kubectl describe svc -n istio-system istio-ingressgateway
#
kubectl stern -l app=webapp -n istioinaction
kubectl stern -l app=catalog -n istioinaction
#
curl -s http://127.0.0.1:30000/api/catalog | jq
curl -s http://127.0.0.1:30000/api/catalog/items/1 | jq
curl -s http://127.0.0.1:30000/api/catalog -I | head -n 1
# webapp 반복 호출
while true; do curl -s http://127.0.0.1:30000/api/catalog/items/1 ; sleep 1; echo; done
while true; do curl -s http://127.0.0.1:30000/api/catalog -I | head -n 1 ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
while true; do curl -s http://127.0.0.1:30000/api/catalog -I | head -n 1 ; date "+%Y-%m-%d %H:%M:%S" ; sleep 0.5; echo; done


[2.4.1 Istio observability] Istio 관찰가능성
# NodePort 변경 및 nodeport 30001~30003으로 변경 : prometheus(30001), grafana(30002), kiali(30003), tracing(30004)
kubectl patch svc -n istio-system prometheus -p '{"spec": {"type": "NodePort", "ports": [{"port": 9090, "targetPort": 9090, "nodePort": 30001}]}}'
kubectl patch svc -n istio-system grafana -p '{"spec": {"type": "NodePort", "ports": [{"port": 3000, "targetPort": 3000, "nodePort": 30002}]}}'
kubectl patch svc -n istio-system kiali -p '{"spec": {"type": "NodePort", "ports": [{"port": 20001, "targetPort": 20001, "nodePort": 30003}]}}'
kubectl patch svc -n istio-system tracing -p '{"spec": {"type": "NodePort", "ports": [{"port": 80, "targetPort": 16686, "nodePort": 30004}]}}'
# Prometheus 접속 : envoy, istio 메트릭 확인
open http://127.0.0.1:30001
# Grafana 접속
open http://127.0.0.1:30002
# Kiali 접속 1 : NodePort
open http://127.0.0.1:30003
# (옵션) Kiali 접속 2 : Port forward
kubectl port-forward deployment/kiali -n istio-system 20001:20001 &
open http://127.0.0.1:20001
# tracing 접속 : 예거 트레이싱 대시보드
open http://127.0.0.1:30004


[2.4.2 Istio for resiliency] catalog에 의도적으로 500에러를 재현하고 retry로 복원력 높이기
#
docker exec -it myk8s-control-plane bash
----------------------------------------
# istioinaction 로 네임스페이스 변경
cat /etc/kubernetes/admin.conf
kubectl config set-context $(kubectl config current-context) --namespace=istioinaction
cat /etc/kubernetes/admin.conf
cd /istiobook/bin/
./chaos.sh 500 100 # 모니터링 : kiali, grafana, tracing
./chaos.sh 500 50 # 모니터링 : kiali, grafana, tracing
kubectl config set-context $(kubectl config current-context) --namespace=default
cat /etc/kubernetes/admin.conf
----------------------------------------

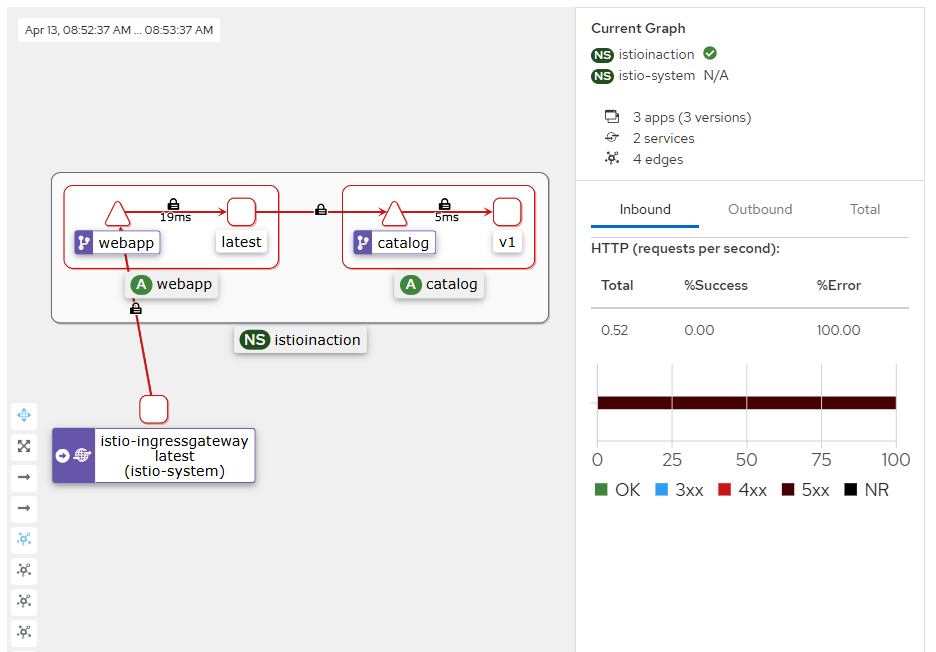
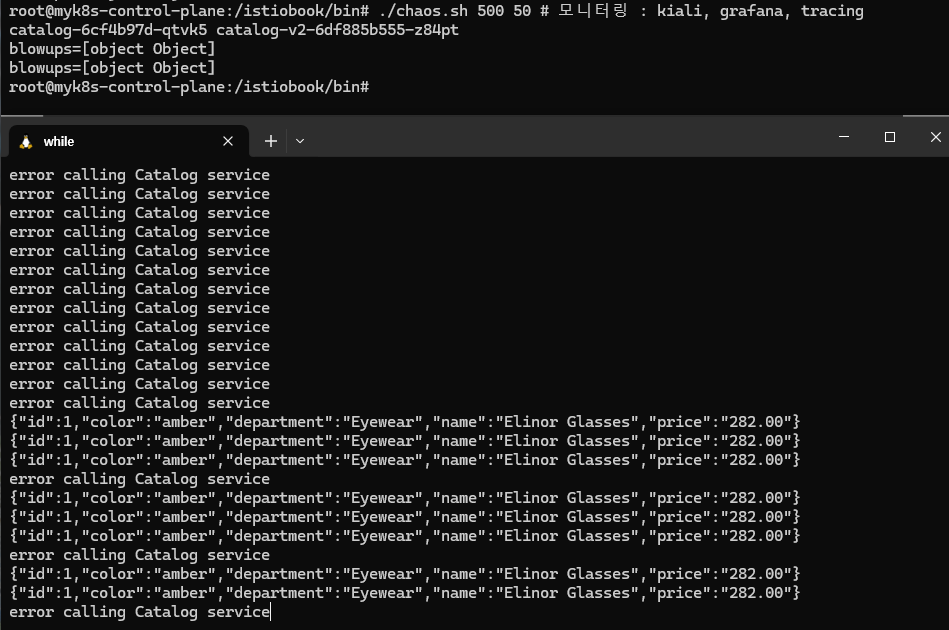
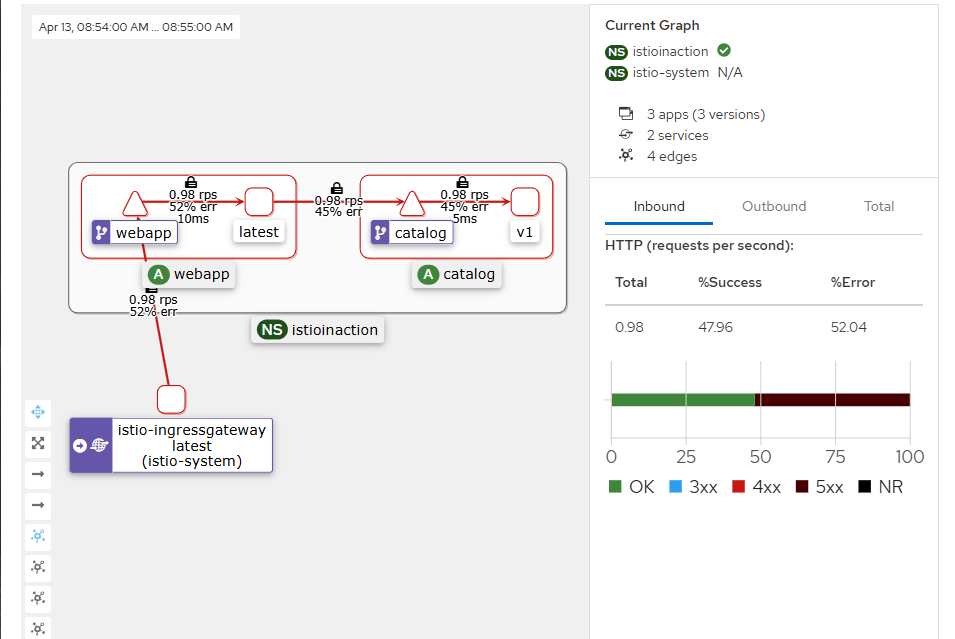
에러 발생 시 reslience 하게 retry
# catalog 3번까지 요청 재시도 할 수 있고, 각 시도에는 2초의 제한 시간이 있음.
cat <<EOF | kubectl -n istioinaction apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: catalog
spec:
hosts:
- catalog
http:
- route:
- destination:
host: catalog
retries:
attempts: 3
retryOn: 5xx
perTryTimeout: 2s
EOF
kubectl get vs -n istioinaction
NAME GATEWAYS HOSTS AGE
catalog ["catalog"] 12s
webapp-virtualservice ["outfitters-gateway"] ["*"] 3h38m

[2.4.3 Istio for Traffic Routing] 새 기능 추가 시나리오 대응
# catalog v2 배포
cat <<EOF | kubectl -n istioinaction apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: catalog
version: v2
name: catalog-v2
spec:
replicas: 1
selector:
matchLabels:
app: catalog
version: v2
template:
metadata:
labels:
app: catalog
version: v2
spec:
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: SHOW_IMAGE
value: "true"
image: istioinaction/catalog:latest
imagePullPolicy: IfNotPresent
name: catalog
ports:
- containerPort: 3000
name: http
protocol: TCP
securityContext:
privileged: false
EOF
# (옵션) 500 에러 발생 꺼두기
docker exec -it myk8s-control-plane bash
----------------------------------------
cd /istiobook/bin/
./chaos.sh 500 delete
exit
----------------------------------------
#
kubectl get deploy,pod,svc,ep -n istioinaction
kubectl get gw,vs -n istioinaction
# 반복 접속 종료해두기

#
cat <<EOF | kubectl -n istioinaction apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: catalog
spec:
host: catalog
subsets:
- name: version-v1
labels:
version: v1
- name: version-v2
labels:
version: v2
EOF
#
kubectl get gw,vs,dr -n istioinaction
# 반복 접속 : v1,v2 분산 접속 확인
while true; do curl -s http://127.0.0.1:30000/api/catalog | jq; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
# v1 라우팅 VS 수정(업데이트)
cat <<EOF | kubectl -n istioinaction apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: catalog
spec:
hosts:
- catalog
http:
- route:
- destination:
host: catalog
subset: version-v1
EOF
# 반복 접속 : v1 접속 확인
while true; do curl -s http://127.0.0.1:30000/api/catalog | jq; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
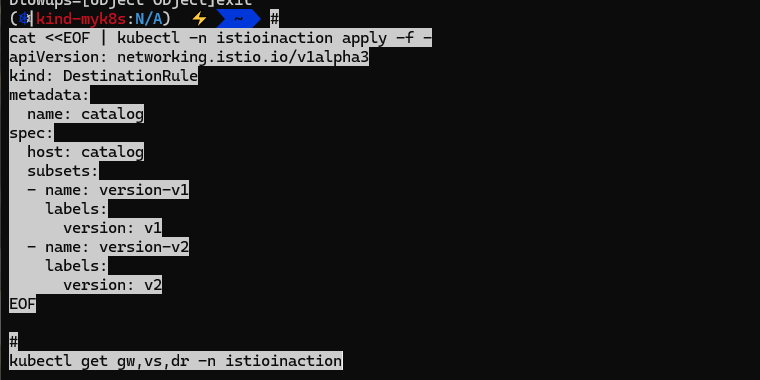



특정 헤더는 v2, 그외에는 v1 접속 설정
# 라우팅 VS 수정(업데이트)
cat <<EOF | kubectl -n istioinaction apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: catalog
spec:
hosts:
- catalog
http:
- match:
- headers:
x-dark-launch:
exact: "v2"
route:
- destination:
host: catalog
subset: version-v2
- route:
- destination:
host: catalog
subset: version-v1
EOF
#
kubectl get gw,vs,dr -n istioinaction
# 반복 접속 : v1 접속 확인
while true; do curl -s http://127.0.0.1:30000/api/catalog | jq; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
# 반복 접속 : v2 접속 확인
while true; do curl -s http://127.0.0.1:30000/api/catalog -H "x-dark-launch: v2" | jq; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done


'스터디 > Istio Hands-on Study' 카테고리의 다른 글
| Istio Hands-on Study [1기] - 5주차 - 마이크로서비스 통신 보안 - 9장 (9.3까지) (0) | 2025.05.09 |
|---|---|
| Istio Hands-on Study [1기] - 4주차 - Observability - 8장 (0) | 2025.05.03 |
| Istio Hands-on Study [1기] - 3주차 - Traffic control, Resilience - 5장 (0) | 2025.04.22 |
| Istio Hands-on Study [1기] - 2주차 - Envoy, Isto Gateway (4.2.3 이후) (1) | 2025.04.20 |
| Istio Hands-on Study [1기] - 2주차 - Envoy, Isto Gateway (4.2.3 이전) (1) | 2025.04.15 |