
정의
카프카(Kafka)는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위한 오픈 소스 분산 이벤트 스트리밍 플랫폼이다.
카프카는 Pub-Sub 모델의 메시지 큐 형태로 동작하고, 분산 환경에 특화되어 있다는 특징이 있다.
그렇다면 이벤트 스트리밍이란 무엇인가?
이벤트 스트리밍은 단순히 다른 시스템에서 쉽게 액세스하고 분석할 수 있도록 장소간에 이벤트 데이터를 효율적으로 이동하는 프로세스를 의미합니다. Apache Kafka는 이벤트 스트리밍 도구의 좋은 예입니다. 따라서 이벤트 스트리밍은 이벤트 스트림 처리 작업의 일부입니다.
음 결과적으로 이벤트 스트리밍이란 연속적으로 들어오는 이벤트들을 다른 시스템으로 효율적으로 전달해주는 것이라고 생각이 든다.
카프카는 링크드인에서 개발했으며 개발 전에는 아래와 같은 아키텍쳐로 구성되어 있었다.

기존 아키텍쳐는 애플리케이션과 DB가 엔드 투 엔드로 구성되어 있고, 요구사항이 늘어날 때마다 데이터 시스템 복잡도가 높아지면서 다음과 같은 문제가 발생했다.
- 시스템 복잡도 증가
- 통합된 전송 영역이 없어 데이터 흐름을 파악하기 어렵고, 시스템 관리가 어려움
- 특정 부분에서 장애 발생 시 연결되어 있는 애플리케이션을 모두 확인해봐야 하기 때문에 장애 조치 시간 증가됨
- HW 또는 SW 업그레이드 시 애플리케이션 단에서 Side Effect가 없는 지 확인해야 해서 관리 포인트가 늘어나고 총 작업 시간 증가
- 데이터 파이프라인 관리의 어려움
- 각 애플리케이션과 데이터 시스템 간의 별도의 파이프라인이 존재하고, 파이프라인 마다 데이터 포맷과 처리 방식이 다름
- 새로운 파이프라인 확장이 어려워지면서, 확장성 및 유연성이 떨어짐
- 데이터 불일치 가능성 증가되어 신뢰도가 감소된다.
위와 같은 문제점을 겪고 모든 이벤트와 데이터의 흐름을 중앙에서 관리해주는 무언가가 필요했다.
카프카 아키텍쳐
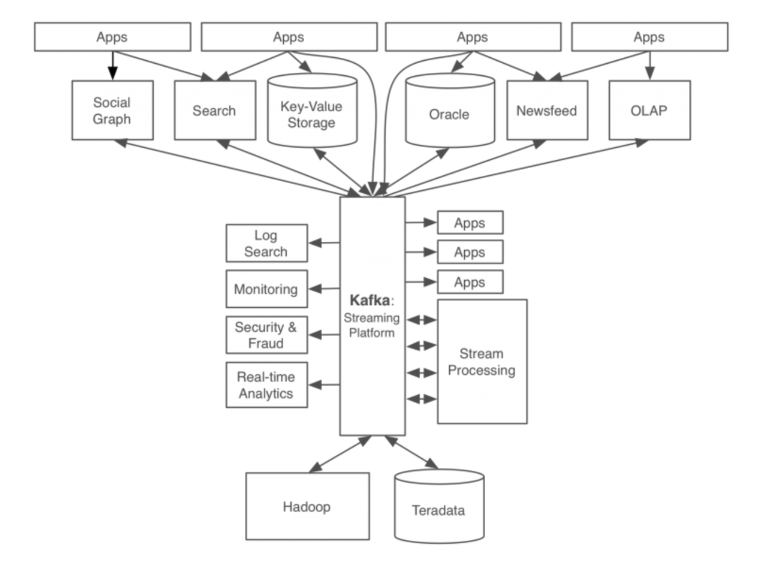

- Event : Kafka 에서 Producer와 Consumer가 데이터를 주고 받는 단위 즉, 메시지
- Producer : Kafka에 이벤트를 게시 (POST, POP) 하는 클라이언트 어플리케이션
- Consumer : Topic을 구독하고 이로부터 얻어낸 이벤트를 받아 (Sub) 처리하는 클라이언트 어플리케이션
- Broker : Kafka 클러스터 내에서 여러 브로커가 함께 작동하여 데이터의 안정성과 확장성을 보장하며, 데이터의 복제와 분산 처리를 관리하고 데이터의 내/외부 이동을 담당한다. 주로 하는 기능은 데이터 저장, 데이터 분배, 데이터 전송
- Topic :
- 토픽은 데이터의 주제나 카테고리. 데이터 스트림을 특정 주제에 따라 구분하기 위한 논리적인 컨테이너 역할을 한다.
- 토픽은 프로듀서가 생성하고, 컨슈머가 구독하는 기반 단위로 사용된다.
- Partition :
- Topic 내에서 데이터를 물리적으로 분할하여 저장하고 처리하기 위한 단위
- 각 Topic은 하나 이상의 Partition으로 구성된다. Partition은 병렬 처리를 가능하게 하고, 데이터를 분산 저장하고 처리함으로 Kafka의 확장성을 지원한다.
- Producer가 데이터를 게시할 때 파티션을 선택하거나 라운드로빈 방식으로 데이터를 파티션에 분배할 수 있다.
- Zookeeper : 리더/팔로워 선택, 토픽 및 파티션 메타데이터 관리, 브로커 동적 구성, 분산 락 관리, 클러스터 감시 및 상태 관리를 하고 Kafka 클러스터의 안정성과 신뢰성을 제공하는데 기여한다.
동작은 이렇게 한다.
- Topic 생성 : 메시지를 전송하기 전에 메시지의 유형 또는 주제를 정의하기 위해 Topic을 생성한다. 각 토픽은 관련된 메시지를 그룹화하는 데 사용된다.
- Producer 설정 : 메시지를 생성하고 카프카로 전송하는 애플리케이션 또는 컴포넌트를 프로듀서라고 부른다. 프로듀서는 카프카 클러스터에 연결하고 메시지를 생성하여 특정 토픽으로 보낸다.
- 메시지 생성 및 전송 : 프로듀서는 메시지를 생성하고, 해당 메시지를 특정 토픽으로 보낸다. 메시지는 주로 JSON 또는 기타 직렬화 형식으로 작성된다.
- 브로커에 메시지 저장 : 프로듀서가 메시지를 보내면, 카프카 브로커는 메시지를 받아서 디스크에 저장한다. 이 메시지는 설정된 유지 기간 동안 보존된다.
- 컨슈머 설정 : 메시지를 소비하려면 컨슈머를 설정해야 한다. 컨슈머는 특정 토픽에서 메시지를 가져와서 처리하는 역할을 한다.
- 메시지 수신 및 처리 : 컨슈머는 카프카 브로커에서 메시지를 가져와서 필요한 처리 작업을 수행한다. 예를 들어 데이터 분석, 저장, 다른 시스템으로 메시지 전달 등의 작업을 수행한다.
- 실시간 모니터링 및 관리 : 카프카 클러스터 및 메시지 흐름을 모니터링하고 필요한 경우 클러스터를 관리한다. 이러한 모니터링은 카프카 클러스터의 안정성과 신뢰성을 유지하는 데 중요하다.
- 확장성 및 관리 : 시스템의 요구 사항이 변하면, 카프카 클러스터를 확장하고 관리하여 대량의 메시지를 처리하고 더 많은 프로듀서 및 컨슈머를 지원할 수 있다.
언제 사용하면 좋은지?
- 대용량 데이터 처리, 실시간, 고성능, 고가용성이 필요한 경우 또는 저장된 이벤트를 기반으로 로그를 추적하고 재처리 하는 게 필요한 경우
- 이 외에 RabbitMQ를 사용하면 좋은 경우 : 복잡한 라우팅을 유연하게 처리하고, 정확한 요청 - 응답이 필요한 Application을 사용하는 경우 또는 트래픽은 작지만 장시간 실행되고 안정적인 백그라운드 작업이 필요한 경우
- 이 외에 Redis를 사용하면 좋은 경우 : 이벤트 데이터를 DB에 저장해 굳이 미들웨어에 이벤트를 저장할 필요가 없는 경우, Consumer에게 굳이 꼭 알람이 도착해야한다는 보장 없이 알람처럼 Push 보내는 것만 중요하다면 유지보수가 편한 Redis 사용
일반 MessageQueue와 어떤 부분이 다른지?
- 데이터 처리 방식
- 카프카는 주로 Pub-Sub 패턴을 사용한다. 여러 Producer가 데이터를 특정 토픽으로 보내고 여러 Consumer가 해당 토픽의 데이터를 구독한다.
- 메시지 큐는 큐 형태의 데이터 전송을 지원하고, 메시지는 FIFO 형태로 처리가 되며 주로 단일 소비자 또는 워커가 데이터를 하나씩 처리하도록 설계 되었다.
- 확장성
- 카프카는 분산 시스템으로, 높은 처리량과 대규모 메시지 스트림을 다루는 데 용이하다. 카프카 클러스터를 확장 해 더 많은 브로커와 파티션을 추가할 수 있으며, 이를 통해 수백만 개의 메시지를 초당 처리할 수 있다.
- 메시지 큐는 주로 단일 큐를 사용해 확장성은 카프카보다 제한된다 .일부 메시지 큐 시스템은 클러스터 구성을 통해서 확장성을 높일 수 있지만 카프카만큼 쉽게 되지는 않는다.
- 지원되는 메시지 유형
- 카프카는 다양한 메시지 형식(텍스트, 바이너리, JSON, 구조화된 이벤트)을 지원하며, 대용량 데이터 스트림 처리 및 이벤트 스트리밍에 적합하다. 카프카 Connect와 같은 플러그인을 통해 다른 시스템과의 통합이 용이하다.
- 메시지 큐는 주로 작은 크기의 메시지 전달을 위해 설계되었으며, 실시간 데이터 스트림 처리를 위한 강력한 도구 및 라이브러리가 카프카에 비해 제한적일 수 있다.
- 사용사례
- 카프카는 대규모 실시간 데이터 스트림 처리, 이벤트 기반 아키텍쳐, 로그 수집, 데이터 파이프라인, 모니터링 및 실시간 분석, 분산 애플리케이션 간 통신, 이벤트 드리븐 아키텍처와 같은 다양한 분야에서 사용된다.
- 메시지 큐는 주로 작업 큐, 이메일 대기열, 알림 전송 등과 같은 비교적 간단한 메시징 요구 사항을 처리하는 데 사용된다.
장단점
- 장점 :
- 대규모 트래픽 처리 및 분산 처리에 효과적이다.
- 클러스터 구성, Fail-Over, Replication 같은 기능이 있다.
- 실시간 애플리케이션 및 분석에 중요한 낮은 대기 시간의 메시지 전달을 제공한다.
- 디스크에 메시지를 특정 보관 주기동안 저장하여 데이터의 영속성이 보장되고 유실 위험이 적다. 또한 Consumer 장애 시 재처리가 가능하다.
- 데이터가 여러 브로커에 복제되어 브로커 장애가 발생하는 경우에도 데이터 가용성을 보장한다.
- 단점 :
- Kafka 클러스터를 관리하기 위해서 분산 시스템에 대한 지식이 필요해 초보자의 경우 설정 및 구성이 복잡할 수 있다.
- Kafka 클러스터를 유지 관리하는 것은 하드웨어, 모니터링 및 관리 측면에서 리소스 집약적일 수 있다.
- 데이터 볼륨이 낮은 애플리케이션에는 비용 효율적이지 않을 수 있다.
- Kafka는 분산 조정을 위해 ZooKeeper를 사용해 추가적인 복잡성과 운영 오버헤드가 발생할 수 있다.
내 생각
우와 재밌다. 브로커 내부에서 파티션이 어떻게 구성되어 있는 지도 정리 해보고 싶긴 한데 생각보다 많은 내용이 있어서 다음에 정리 해볼까 한다. 나중에 카프카 관련된 책으로 구체적으로 공부를 해보는 것도 좋을 것 같다.
[참조] :
https://jaehoney.tistory.com/197
https://medium.com/swlh/apache-kafka-what-is-and-how-it-works-e176ab31fcd5
'CS 지식' 카테고리의 다른 글
| DNS 플러쉬(Flush)란? (0) | 2023.11.09 |
|---|---|
| robots.txt 파일이란? (1) | 2023.11.08 |
| 서킷 브레이커(Circuit Breaker)란? (0) | 2023.09.25 |
| 컴퓨터 구조란? (0) | 2023.08.09 |
| 비동기와 동기란? (0) | 2023.07.25 |